Talend 模糊匹配或 tFuzzyMatch 组件将源数据(主表)列值与参考表(查找表)进行比较。模糊匹配会将查找表中的匹配值及其整数形式的距离值返回。
Talend 模糊匹配在纠正数据输入时的输入错误方面非常有用。通过使用此模糊匹配,我们可以简单地将传入数据与数据库中存储的原始表进行比较,并纠正错误。
在此 Talend 模糊匹配示例中,我们使用文本文件作为源或主表数据,使用 SQL 数据库作为查找表。下面的屏幕截图显示了原始表中的数据。
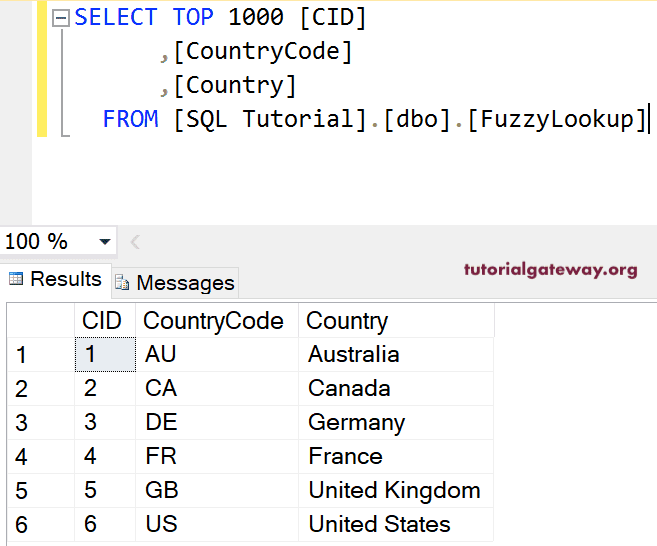
源文本文件是

Talend 模糊匹配示例
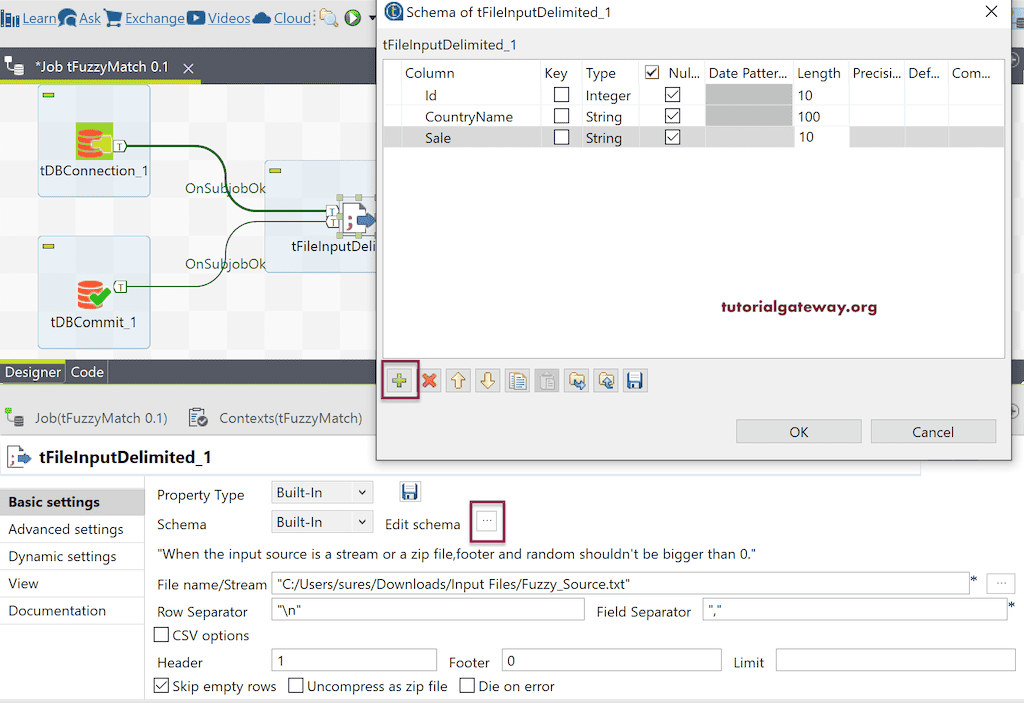
首先,拖放 tDBConnection 和 tDBCommit 以建立 SQL 连接并关闭连接。接下来,将 tFileInputDelimited 从调色板拖到作业设计中。从下方可以看到,我们正在从源中选择文本文件,将字段分隔符更改为逗号,并通过放置“1”来跳过标题行。

请单击“编辑模式”以添加列、数据类型和长度。如果您使用元数据,则可以跳过此步骤。
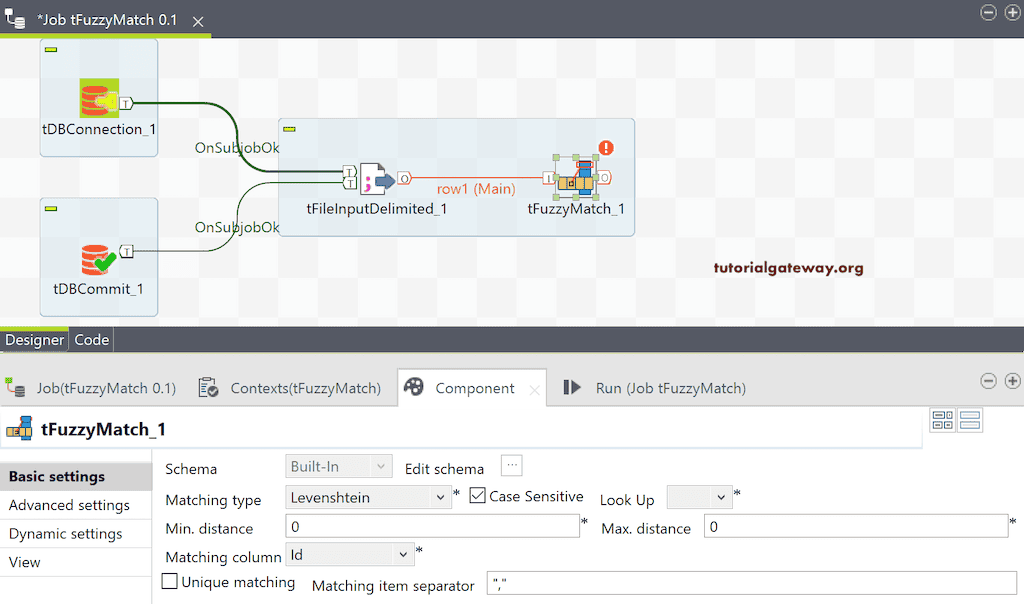
接下来,将 Talend tFuzzyMatch 拖到作业设计中,并将 tFileInputDelimited 的主行连接到它。
在 Talend Fuzzy Match 组件选项卡中,默认选择 Levenshtein 类型。但是,您可以从可用列表中更改它们,它们是
- Levenshtein:此算法计算给定单词与查找值匹配所需的总插入、更新或删除次数。Talend tFuzzyMatch 会根据整数值从查找表中返回匹配的单词。
- Metaphone 使用语音算法,该算法基于单词的发音。它首先加载所有查找表记录,然后检查主表单词与查找表的发音。
- Double Metaphone:原始算法的升级新版本。根据我们的理解,它比原始版本能返回更好的结果。
最小和最大距离:请指定允许与查找单词匹配的更改次数。0 表示完全匹配。
唯一匹配:如果有多个匹配项,请单击此选项以获取最佳匹配项。
Talend tFuzzyMatch 需要一个查找表。因此,我们从 SQL 数据库中选择 FuzzyLookup 表。
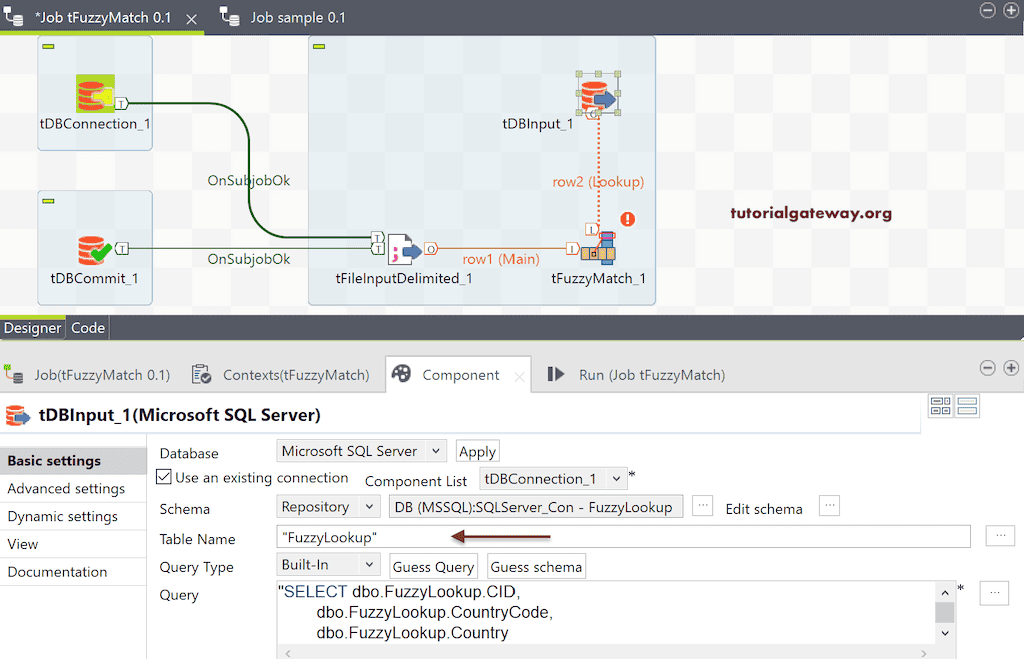
请选择查找列,即包含公共数据的列。在这里,我们想将文本文件中的国家名称与查找表进行比较,以查找拼写错误。因此,我将 row2.Country 选为查找列。
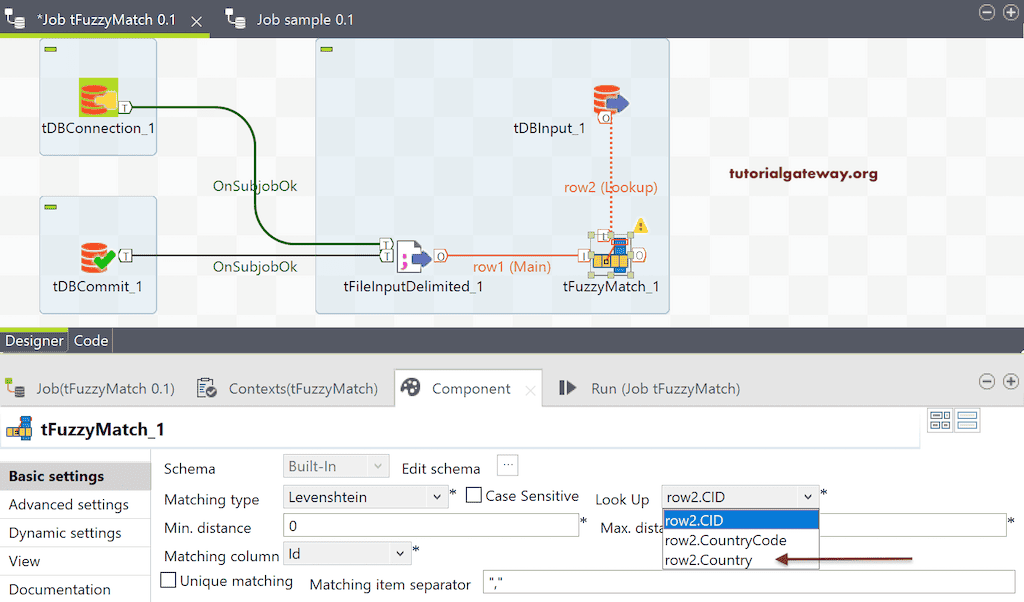
接下来,将匹配列更改为 Country Name,并将 mat distance 更改为 1。
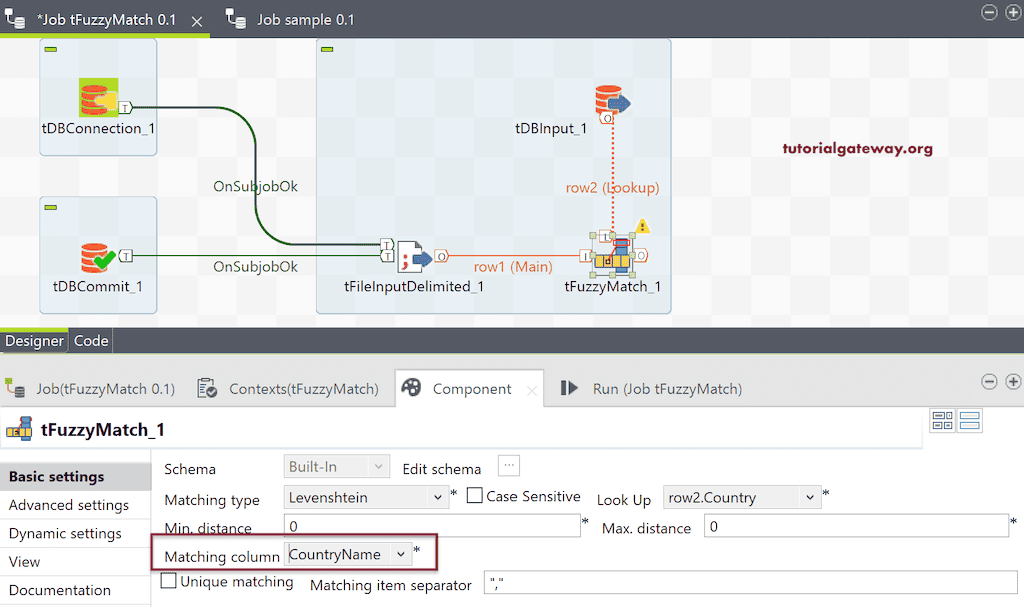
我将使用 tDBOutput 将模糊匹配记录保存在 Talend FuzzyMatch 表中。
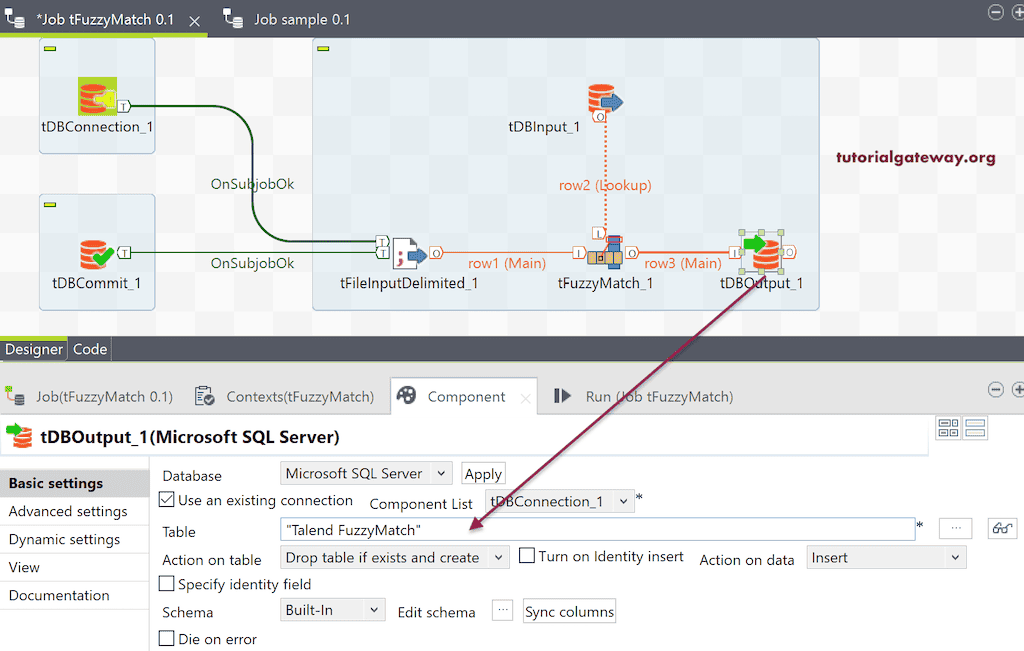
让我们运行 Talend tFuzzyMatch 作业。
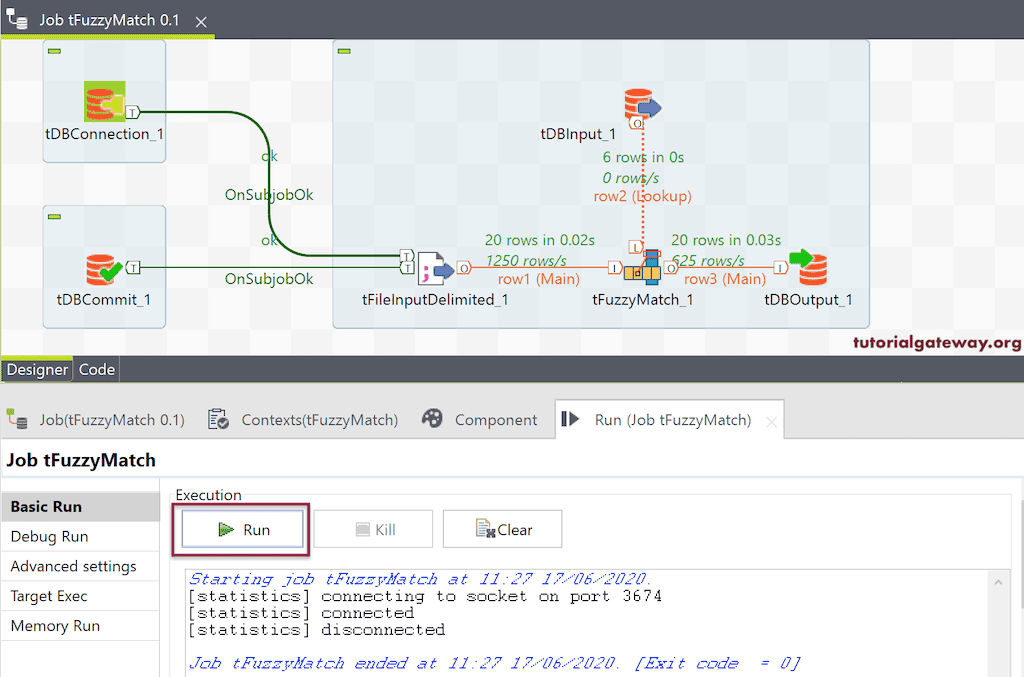
在 Management Studio 中,您可以看到它显示了正确的匹配记录。这意味着 Value 1 将执行严格的比较。
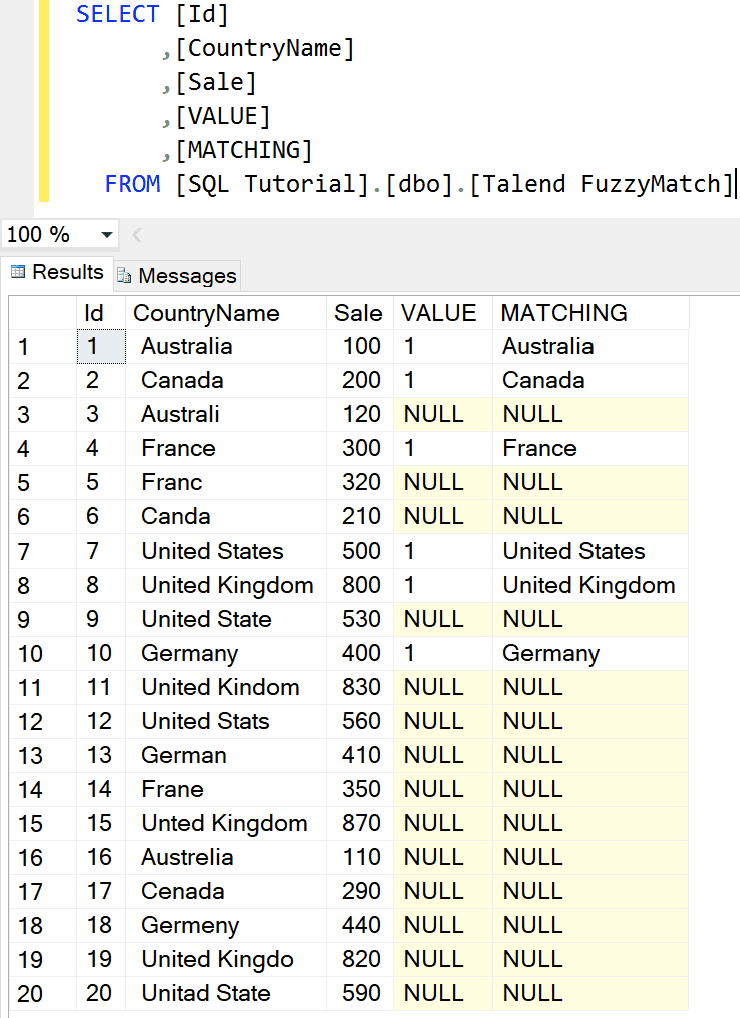
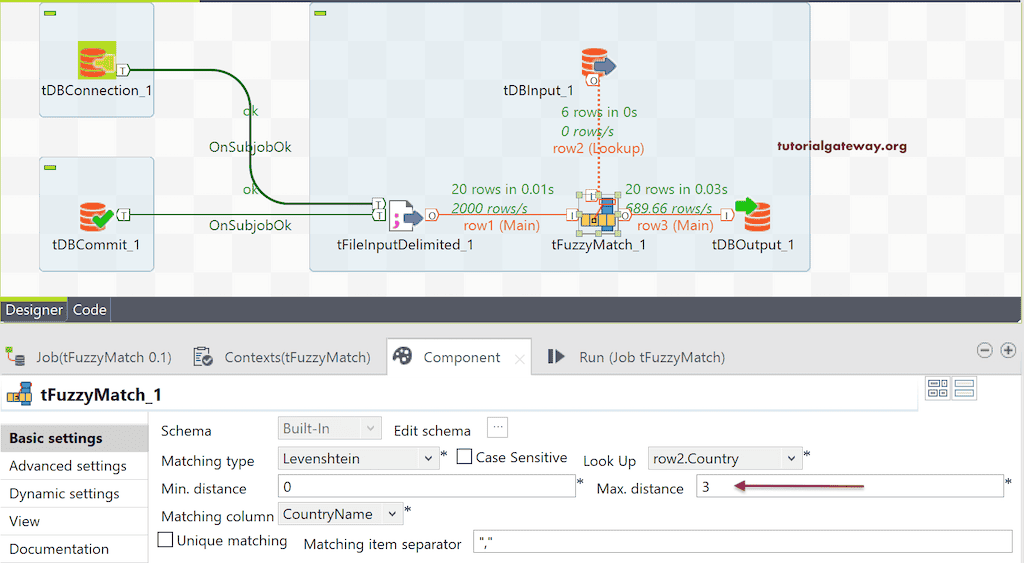
我将 Max distance 更改为 3 并运行 Talend 模糊匹配作业。
现在,您可以在 SQL 中看到所有拼写正确的记录。
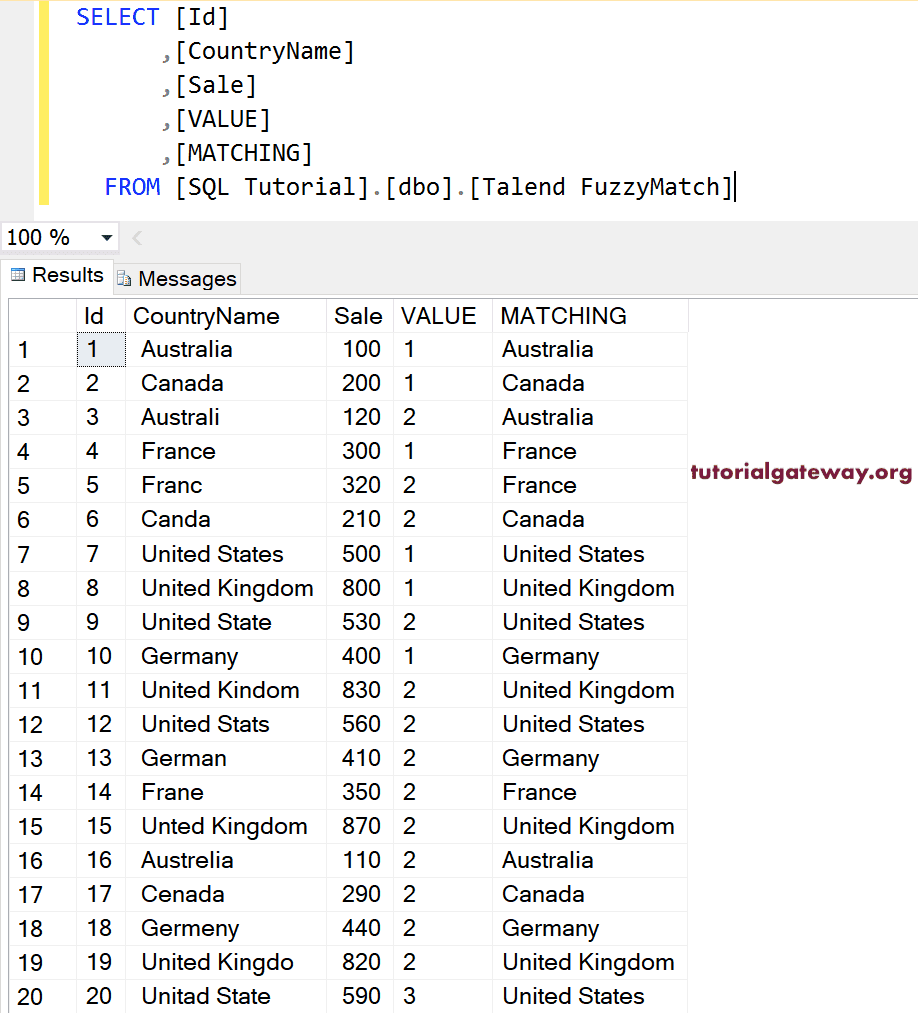
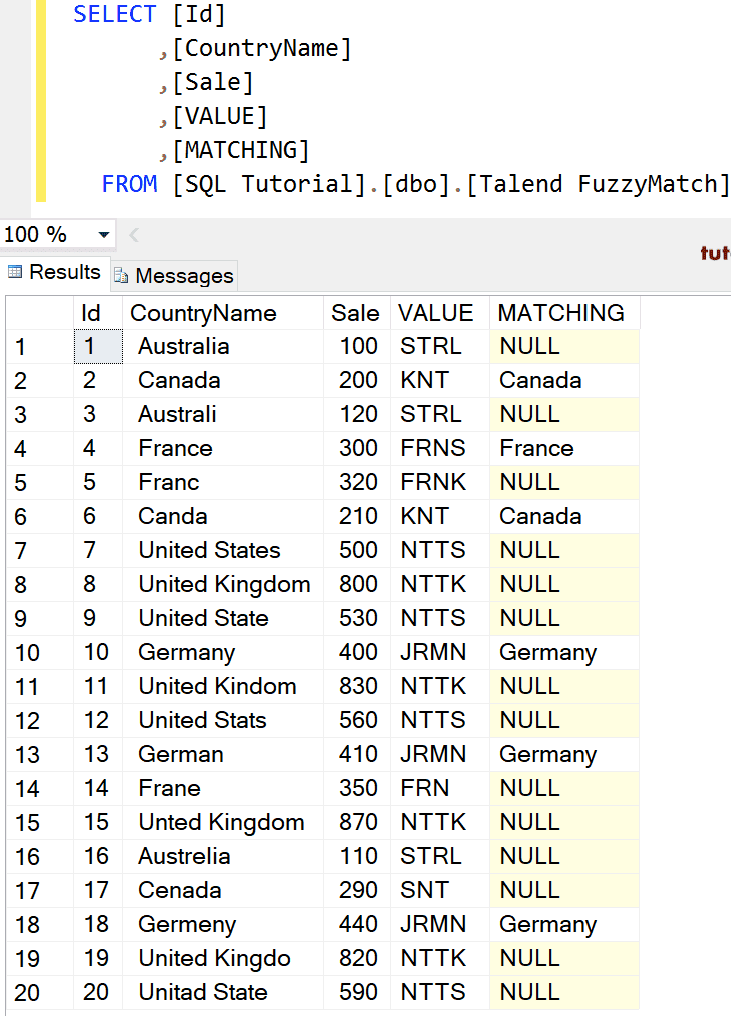
这次,我们将匹配类型更改为 Metaphone。
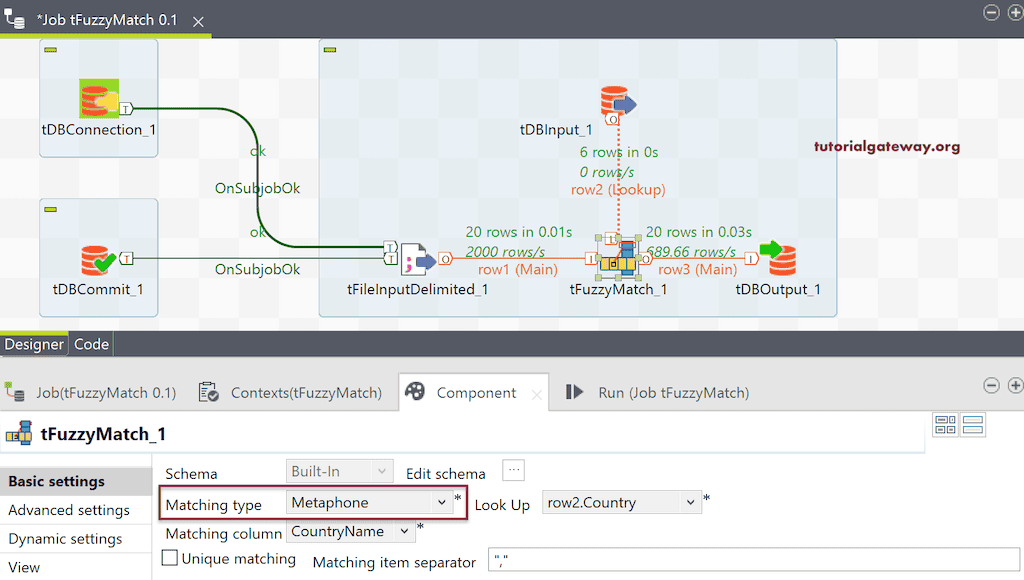
模糊匹配的结果是
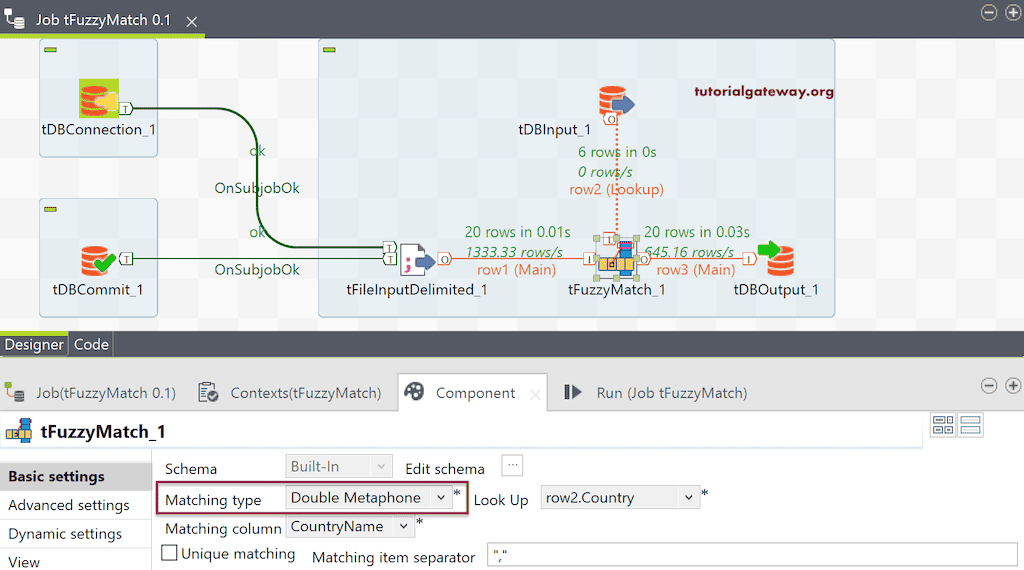
让我们将 Talend 模糊匹配类型更改为 Double Metaphone。
它会显示当将文本文件中的国家与查找表中的国家名称进行比较时,发音相同的国家。
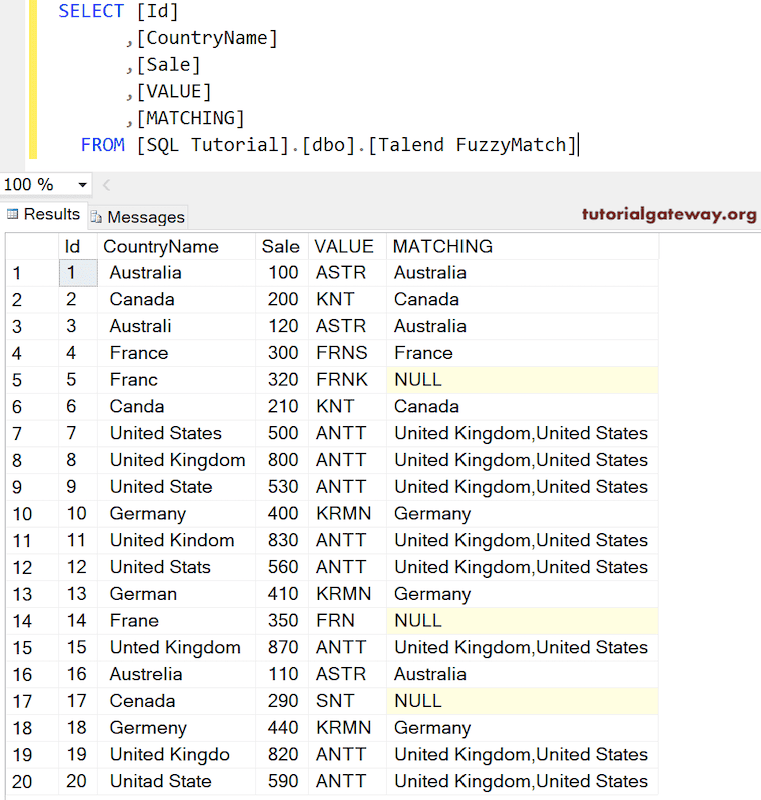
如果选择 Unique 选项以及 Double Metaphone,则模糊匹配输出是。
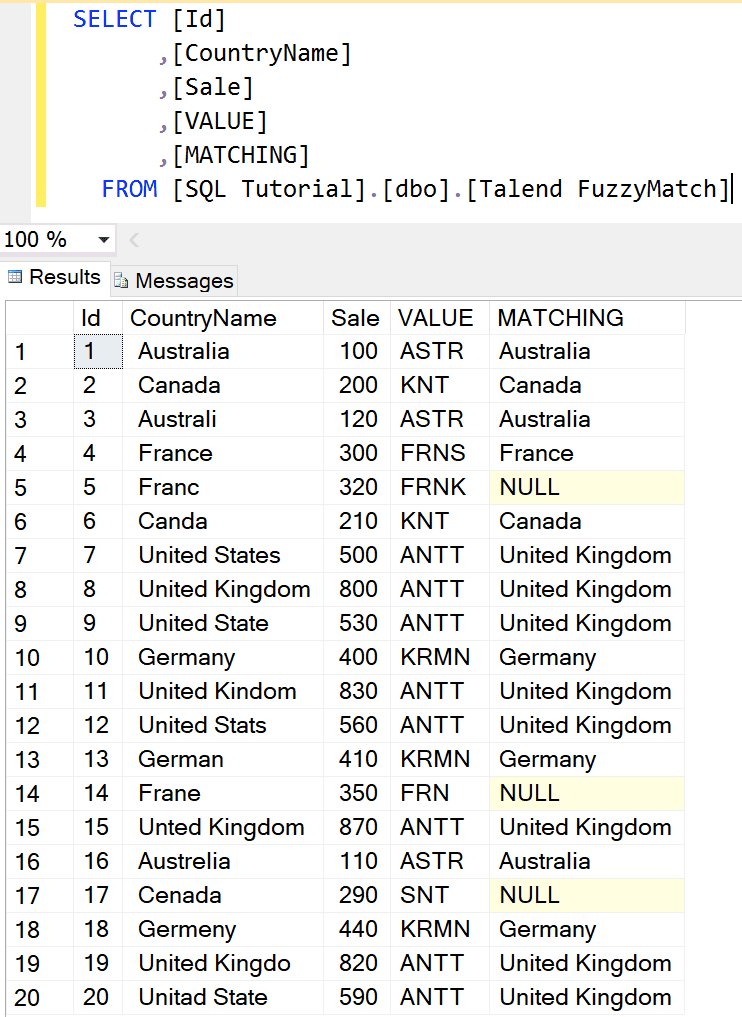
注意:如果记录更多,Talend tFuzzyMatch 的结果可能会有所不同。