SQL Server 的 RANK 函数将为分区中的每个记录分配排名编号。如果 RANK 函数在同一分区中遇到两个相等的值,它将为这两个值分配相同的编号,并跳过下一个编号。
SQL Server rank 函数的语法如下所示。
SELECT RANK() OVER (PARTITION_BY_Clause ORDER_BY_Clause) FROM [Source]
Partition_By_Clause:这将按 SELECT 语句选择的记录进行分区。如果您指定 Partition By Clause,则 RANK 函数将为每个分区分配编号。如果您未指定,它会将所有记录视为一个部分,并从上到下分配编号。
在此 RANK 函数示例中,我们将使用以下表数据。
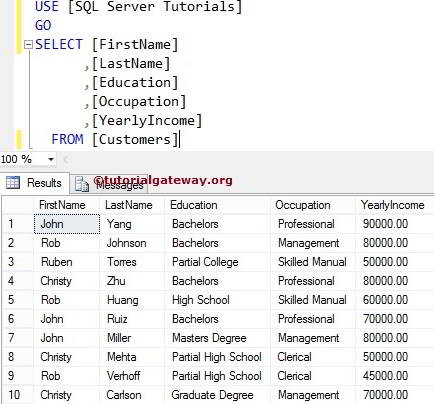
SQL Server RANK 函数示例
它允许您为分区中的每个记录分配编号。在此示例中,我们将向您展示如何对表中的分区行内的行进行排名。以下 Select Statement 将按职业对数据进行分类,并使用年收入分配编号。
SELECT [FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,RANK() OVER (
PARTITION BY [Occupation]
ORDER BY [YearlyIncome] DESC
) AS RANK
FROM [Customers]
它使用职业将选定的数据划分为分区。您可以从上面的 Server 示例输出中看到,我们有四个部分。
PARTITION BY [Occupation]
以下 Order By 语句将使用其 [年收入] 按降序对分区数据进行排序。
ORDER BY [YearlyIncome] DESC
我们使用了带 Partition by 子句的 RANK 函数。因此,它将为每种职业分配编号。
RANK() OVER (
PARTITION BY [Occupation]
ORDER BY [YearlyIncome] DESC
) AS RANK
由于第 3 和第 4 条记录的年收入相同,因此它们获得了相同的编号。接下来,它跳过了一个编号,并为下一条记录分配了第 3 位。
SQL Server RANK 函数(不带 Partition By Clause)
在此示例中,我们将向您展示,如果我们遗漏或不使用 Partition By Clause 会发生什么。例如,它将使用不带 Partition by 子句的上述示例查询。
SELECT [FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,RANK() OVER (
ORDER BY [YearlyIncome] DESC
) AS RANK
FROM [Customers]
我们使用了不带 Partition by 子句的 RANK 函数。因此,此函数将其视为一个类别,并从头到尾分配编号。
RANK() OVER (
ORDER BY [YearlyIncome] DESC
) AS RANK
由于第 2、3 和 4 条记录的年收入相同,因此它们获得了相同的编号。接下来,它为这两条记录(第 3、4 条)跳过了两个编号,并为下一条记录分配了第 5 位。
对字符串列进行排名
它还允许您对字符串列进行排名。在此示例查询中,我们使用此 SQL Server 函数为字符串列名(First name)分配排名编号。
SELECT [LastName]
,[Education]
,[YearlyIncome]
,[Occupation]
,[FirstName]
,RANK() OVER (
PARTITION BY [Occupation]
ORDER BY [FirstName] DESC
) AS RANK
FROM [Customers]
由于第 6 和第 7 条记录的名(First name)相同,因此它们获得了相同的编号。接下来,它跳过了一个编号,并为下一条记录分配了第 3 位。