Microsoft 于 2008 年在 SQL Server 中引入了 MERGE 语句,用于在单个语句中执行 INSERT、DELETE 和 UPDATE。它是同步两个不同表数据的最强大语句之一。我们可以使用它来执行 ETL 操作(数据集成任务),尤其是在没有其他操作正在进行时处理大型数据集。您可以使用此 SQL MERGE 语句在单个语句中执行以下三个操作:
- 使用源表更新目标表中的现有记录。
- 将全新的记录插入表中。
- 删除不再需要或与当前场景不匹配的记录。
什么是 SQL MERGE 语句?
如前所述,SQL Server MERGE 语句是一个单一语句,您可以在其中一次性执行 INSERT、DELETE 和 UPDATE。因此,无需为这些 DML 操作使用多个语句,即可使用 MERGE 查询。由于单个语句执行多个操作,因此查询性能可能会显著提高。但是,性能可能取决于表数据排序顺序、索引、表连接等。如果我们使用记录较少的简单表,它的效果会非常好。
它需要一个或多个源表,根据连接条件将它们与目标表数据合并。这意味着 MERGE 语句首先将所需表与目标表或视图连接起来。接下来,它对它们执行所需的 DML 操作。因此,根据源表中的数据修改目标表中存在的数据非常有用。
SQL MERGE 语句语法
使用此语句的常见场景之一是维护数据仓库中的 SCD(缓慢变化维度)。SQL MERGE 语句的语法用于在目标表中执行插入、更新和删除行(UPSERT)操作。
MERGE [TOP (expression) [PERCENT] ]
INTO [Destination_table] AS ds
USING [Source_Table] AS st -- Include the columns Name
ON ds.[Common column] = st.[Common Column]
-- It's not about matching, You have to add the expressions
WHEN MATCHED [ AND <search_condition> ]
THEN UPDATE | DELETE
WHEN NOT MATCHED [BY TARGET] [ AND <search_condition> ]
THEN INSERT
WHEN NOT MATCHED [BY SOURCE] [ AND <search_condition> ]
THEN DELETE
您可以将上述语法的完整语句包装在 通用表表达式 中。可选的 TOP 子句通过指定行数或百分比来限制总行数。
从上面的语法可以看出,它会在 MATCHED 子句之后进行检查并执行操作。让我们详细探讨 SQL MERGE 语句的每个部分。
Destination_table: 发生更改的表或用户定义的视图。这意味着 Destination_table 是 WHEN CLAUSE 指定插入、删除或更新操作的位置。
Source_Table: 这是根据 joining condition 与 Destination_table 匹配的实际源数据。此条件匹配结果决定了对 Destination_table 的操作。例如,如果存在匹配的记录,您可能会将服务器推送到更新或删除记录。
AS:表的别名。请参阅 别名列 文章。
ON: 在此关键字之后,您必须指定一个特定的匹配条件来连接源表和目标表。这里,您应该只使用两个表中的公共列进行匹配。如果您尝试添加多个条件来过滤记录(为了提高查询性能),可能会导致返回奇怪且意外的结果集。
AND 运算符: 它有助于添加附加条件。请参阅 AND 运算符 文章。
WHEN MATCHED THEN: 指定当源表和目标表中存在匹配行时应执行的操作,通常是 UPDATE。当目标表中存在匹配记录时,通常的任务是用新值进行更新,例如更新产品价格、员工部门等。
通常,它后面会跟着附加的 DML 操作,因此该操作仅针对满足条件的行执行。
Microsoft SQL Server 允许 MERGE 语句最多有两个 WHEN MATCHED THEN 子句。当您使用两个子句时,一个子句必须指定 UPDATE,另一个必须是 DELETE 操作。此外,第一个子句必须后跟 DELETE 语句。请记住,第二个 WHEN MATCHED 子句将在第一个子句不适用时应用。
WHEN NOT MATCHED [BY TARGET] THEN: 指定当目标表中不存在源表的匹配记录时应执行的操作,通常是 INSERT 操作。
WHEN NOT MATCHED [BY SOURCE] THEN: 指定当目标表中存在额外记录但源表中不存在匹配记录时应执行的操作。在这种情况下,可以删除它们,或者在某些情况下更新它们。
与 WHEN MATCHED 子句类似,MERGE 语句允许两个 WHEN NOT MATCHED [BY SOURCE] 子句。工作功能相同。
SQL MERGE 语句的基本规则
虽然 MERGE 语句的语法以特定顺序显示 WHEN [NOT] MATCHED 子句,但实际上,您可以根据需要以任何顺序指定它们。但是,您必须至少使用上述三个 MATCHED 子句之一。
- 在 SQL Server MERGE 语句中,您必须指定要执行插入、删除或更新(UPSERT)操作的表名或视图。
- 在 USING 子句中指定要联接的数据源。
- ON 子句用于 JOIN 源表和目标表。在这里,您必须指定要用于连接两个表的公共列名。请为源表和目标表指定一些唯一的组合。
- 如果在 ON 子句中不使用键列,您将得到重复的行并最终出错。
- 您可以根据从 WHEN 子句(WHEN NOT MATCHED 和 WHEN MATCHED)获得的结果执行删除、插入或更新操作。
- 在同一个 MATCHED 子句中,您不能多次更新同一个变量。
- 您必须使用分号(;)终止此语句。否则,查询将引发 10713 错误。
- 如果在 MERGE 语句之后使用 @@ROWCOUNT,它将返回插入、删除和更新的行数。
SQL MERGE 语句的最佳实践
如果您遵循以下最佳实践,您将
- 始终在 ON 子句中使用具有适当索引的列,因为它可以提高性能。例如,在源表和目标表上的连接列(如产品 ID、员工 ID 等)上创建索引。
- 处理大型数据集时要小心。没有经过适当优化的表,单个 DML 操作的性能会优于 SQL Server MERGE 语句。因此,请先在小数据集上进行测试,并在解决问题后,在大型数据集上实施查询。
- 请使用临时表或通用表表达式(CTE)来预处理数据。
- 在生产服务器上实施代码之前,务必对其进行测试。
- 始终使用事务来包装 MERGE 语句,以便在出现问题时可以回滚到原始状态。
在此 MERGE 语句示例演示中,我们使用了两个表(Cust 和 Rest)。Rest 表有八条记录。
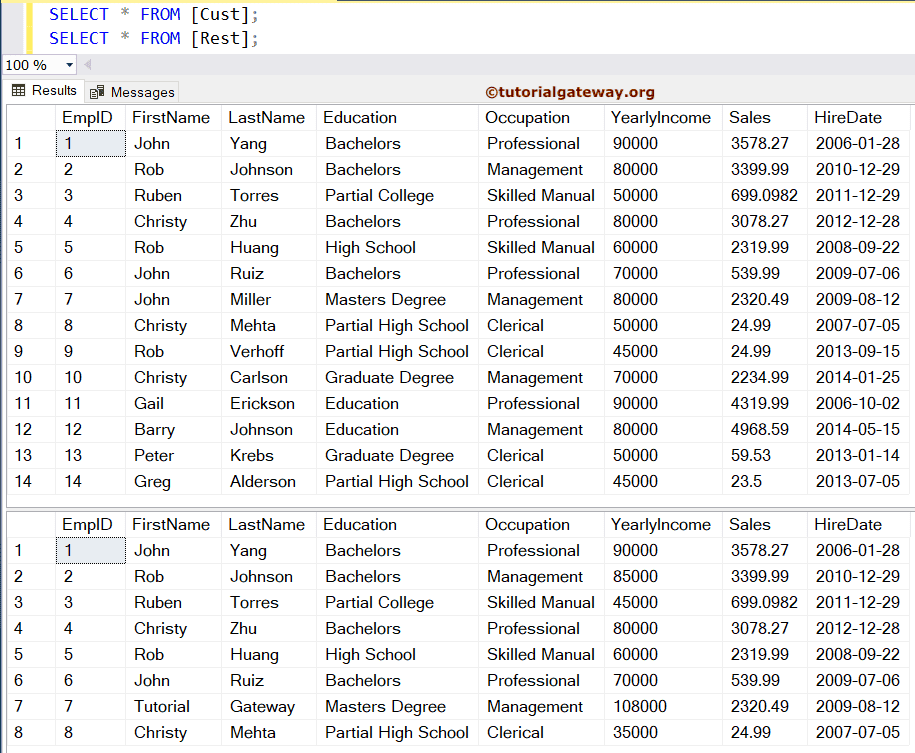
SQL MERGE 如何工作:基本示例
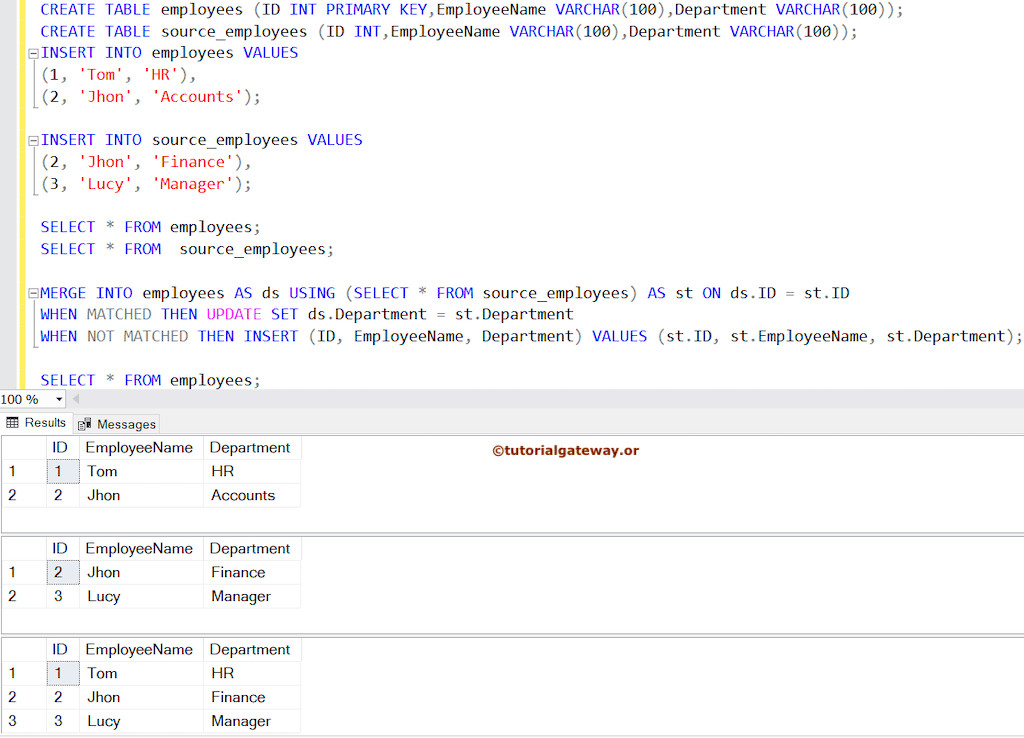
让我们探索一个简单而基本的示例,我们将从源同步(DML 操作)员工数据到目标表。
CREATE TABLE employees (
ID INT PRIMARY KEY,
EmployeeName VARCHAR(100),
Department VARCHAR(100)
);
CREATE TABLE source_employees (
ID INT,
EmployeeName VARCHAR(100),
Department VARCHAR(100)
);
INSERT INTO employees VALUES
(1, 'Tom', 'HR'),
(2, 'Jhon', 'Accounts');
INSERT INTO source_employees VALUES
(2, 'Jhon', 'Finance'),
(3, 'Lucy', 'Manager');
目标表:employees
| ID | EmployeeName | 部门 |
| 1 | Tom | HR |
| 2 | Jhon | Accounts |
源表:source_employees
| ID | EmployeeName | 部门 |
| 2 | Jhon | Finance |
| 3 | Lucy | Manager |
用于同步两个表数据的查询是
MERGE INTO employees AS ds
USING (SELECT * FROM source_employees) AS st
ON ds.ID = st.ID
WHEN MATCHED THEN
UPDATE SET ds.Department = st.Department
WHEN NOT MATCHED THEN
INSERT (ID, EmployeeName, Department)
VALUES (st.ID, st.EmployeeName, st.Department);
输出将是
- 员工 Jhon 的部门已从 Accounts 更新为 Finance。
- 新员工记录 Lucy 将被插入 employee 表中。
如果您观察上面的示例,我们没有在 MATCHED 子句之后使用任何额外的或附加的 WHERE 子句。但是,在实际操作中,我们可能需要使用额外的 WHERE 子句。以下示例将有助于您理解。
使用 SQL MERGE 执行 INSERT 和 UPDATE 操作
在实际操作中,将新记录插入数据库并使用新信息更新旧数据是常见的任务。为了实现这一点,我们必须先编写一个 UPDATE 语句,然后编写一个 INSERT 语句。使用 MERGE 语句,您可以避免这两者,并在单个语句中执行操作。下面的示例将向您展示一个简单的示例,以便您更好地理解。
MERGE INTO [Rest] AS rs
USING (SELECT * FROM [Cust]) AS ct
ON rs.EmpId = ct.EmpId
WHEN MATCHED AND rs.[YearlyIncome] <> ct.[YearlyIncome] THEN
UPDATE SET rs.[YearlyIncome] = ct.[YearlyIncome]
WHEN NOT MATCHED THEN
INSERT ([FirstName],[LastName],[Education],[Occupation],[YearlyIncome],[Sales],[HireDate])
VALUES(ct.[FirstName],ct.[LastName] ,ct.[Education],ct.[Occupation],ct.[YearlyIncome]
,ct.[Sales],ct.[HireDate]);
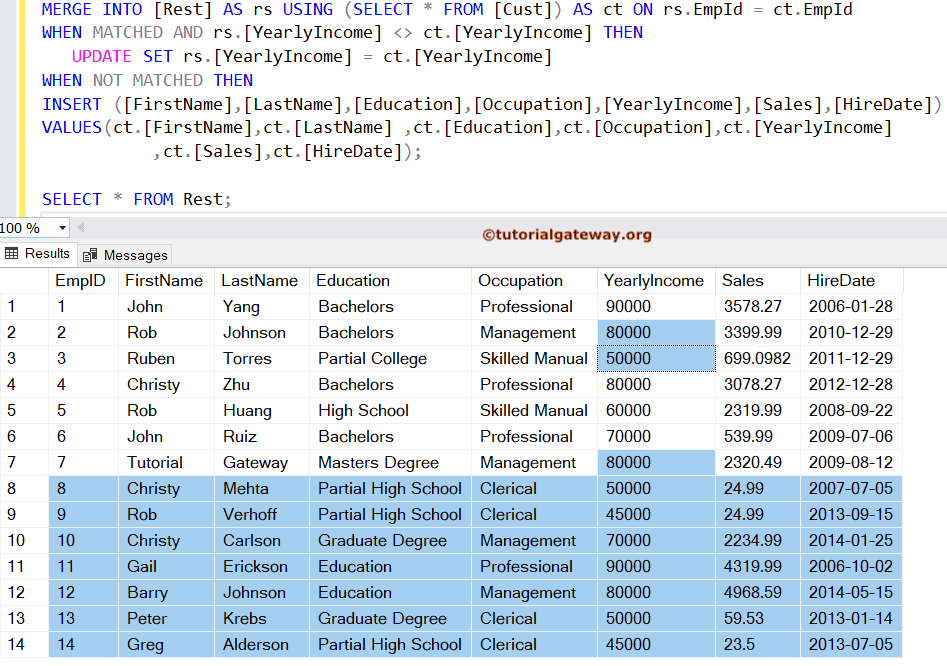
上述示例执行了对表的条件更新,从而避免了对表的不必要锁定。如果没有匹配的记录可供更新,它将把这些记录插入到 Rest 表中。
使用 MERGE 执行 UPDATE 和 DELETE 操作
除了上述情况,在某些情况下,我们需要删除过时的产品(与当前业务无关)。并更新交易产品的定价。为了实现这一点,您需要使用 UPDATE 和 DELETE 语句的组合,或者使用简单的 SQL MERGE 语句。
这个示例与上面的示例略有不同,因为我们将使用 Rest 来更新 Cust 表。因此,我们将 Rest 作为源,并对 Cust 表执行 UPDATE 和 DELETE。正如我们所知,Rest 表有八条记录,下面的查询删除了多余的六条记录,并在有任何更改时更新这 8 条记录的年收入。
MERGE INTO [Cust] AS ct
USING (SELECT * FROM [Rest]) AS rs
ON ct.EmpId = rs.EmpId
WHEN MATCHED AND ct.[YearlyIncome] <> rs.[YearlyIncome] THEN
UPDATE SET ct.[YearlyIncome] = rs.[YearlyIncome]
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
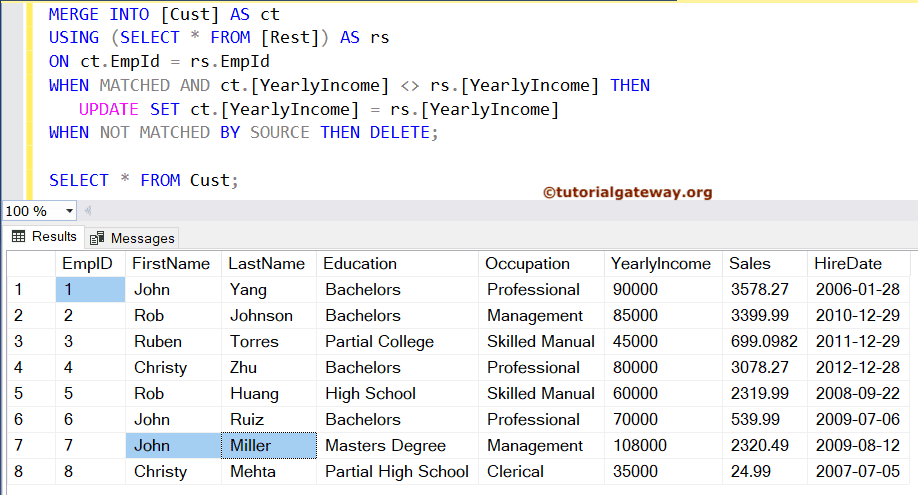
SQL Server MERGE 语句执行 UPDATE、INSERT 和 DELETE 操作
以下查询对 Rest 使用 Cust 表执行插入、删除和更新操作。
MERGE [Rest] AS mrg
USING (SELECT * FROM [Cust]) AS emp
ON mrg.EmpId = emp.EmpId
WHEN MATCHED AND mrg.[YearlyIncome] <= 50000 THEN DELETE
WHEN MATCHED AND mrg.[YearlyIncome] >= 80000 THEN
UPDATE SET mrg.[YearlyIncome] = mrg.[YearlyIncome] + 35000
WHEN NOT MATCHED THEN
INSERT ([FirstName],[LastName],[Education],[Occupation]
,[YearlyIncome],[Sales],[HireDate])
VALUES(emp.[FirstName],emp.[LastName],emp.[Education]
,emp.[Occupation],emp.[YearlyIncome],emp.[Sales],emp.[HireDate]);
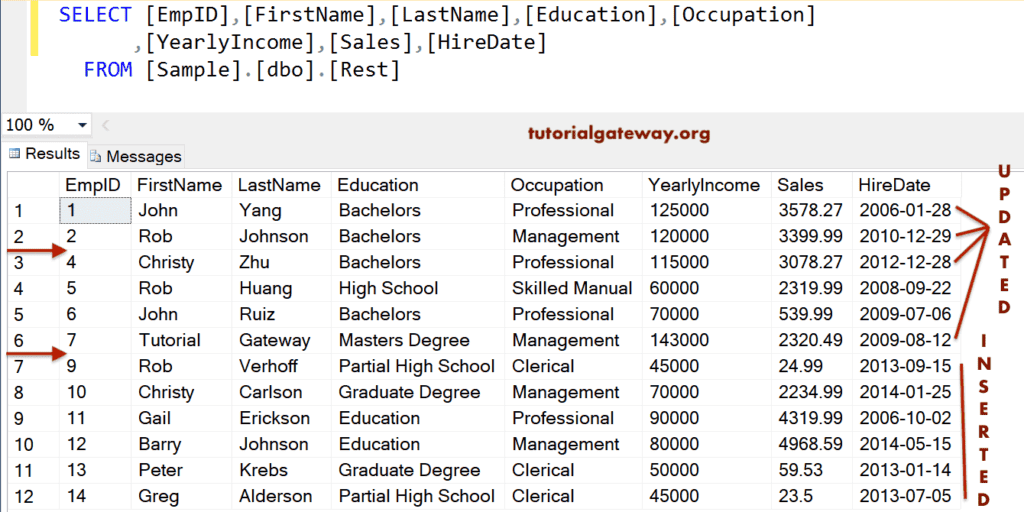
首先,我们在 Merge 子句中使用上面的表。这意味着我们想对 Rest 执行插入、删除和更新操作。
接下来,我们在 SQL Server USING 子句中使用 Cust。这意味着我们想将 Rest 与此数据源连接起来。
USING (SELECT * FROM [Cust]) AS emp
它检查是否有任何员工的年收入小于或等于 50000。如果是 TRUE,则从 Rest 中删除这些记录。在实际操作中,您也可以使用此方法从 Rest 中删除值与源不匹配的记录。
WHEN MATCHED AND mrg.[YearlyIncome] <= 50000 THEN DELETE
下一个语句检查是否有任何员工的年收入大于或等于 80000。如果是匹配的,则通过向 Rest 表中的每条记录添加 35000 来更新这些记录的集合。再次,请参阅 UPDATE 语句 文章。
WHEN MATCHED AND mrg.[YearlyIncome] >= 80000 THEN UPDATE SET mrg.[YearlyIncome] = mrg.[YearlyIncome] + 35000
下一个语句将 Cust 表中不匹配的记录插入到 Rest。请参阅 INSERT 语句 文章以了解其功能。
WHEN NOT MATCHED THEN
INSERT ( .....
........)
在 SQL MERGE 语句中使用事务
以下查询是使用 MERGE 语句的最佳方法。因为我们将整个查询包装在 事务 中以实现原子性。每当您执行 MERGE 操作时,请尝试将代码放在事务中(BEGIN TRAN ….. ROLLBACK TRAN)。如果出现任何问题或任何操作失败,它将回滚所有内容到原始状态。
BEGIN TRAN;
MERGE Rest AS mrg USING (SELECT * FROM [Cust]) AS ct
ON mrg.EmpId = ct.EmpId
WHEN MATCHED AND mrg.[YearlyIncome] <= 50000 THEN DELETE
WHEN MATCHED AND mrg.[YearlyIncome] >= 80000 THEN
UPDATE SET mrg.[YearlyIncome] = mrg.[YearlyIncome] + 35000
WHEN NOT MATCHED THEN
INSERT ([FirstName],[LastName],[Education],[Occupation]
,[YearlyIncome],[Sales],[HireDate])
VALUES(ct.[FirstName],ct.[LastName],ct.[Education]
,ct.[Occupation],ct.[YearlyIncome],ct.[Sales],ct.[HireDate])
OUTPUT $action, inserted.*, deleted.*; -- Only to show the Actions
ROLLBACK TRAN;
GO
通常,OUTPUT 子句返回我们在表中插入、删除和更新的数据的副本。这就是为什么我们将 OUTPUT 子句与 Merge 语句一起使用来显示查询的原因。
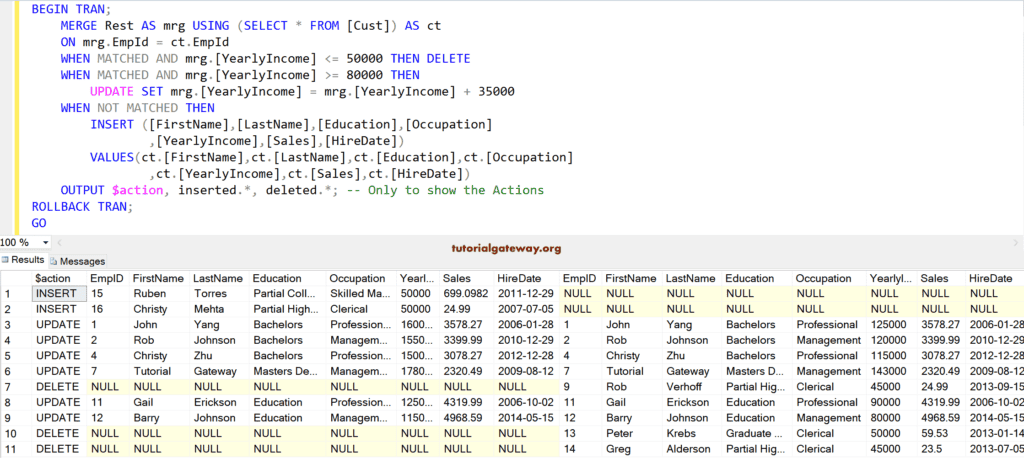
以下语句代码将提供对打印操作结果的更多控制。
SQL Server MERGE 语句 OUTPUT 子句
OUTPUT 子句有助于跟踪表更改。它包括在 MERGE 操作期间行是否已更新、删除或插入。
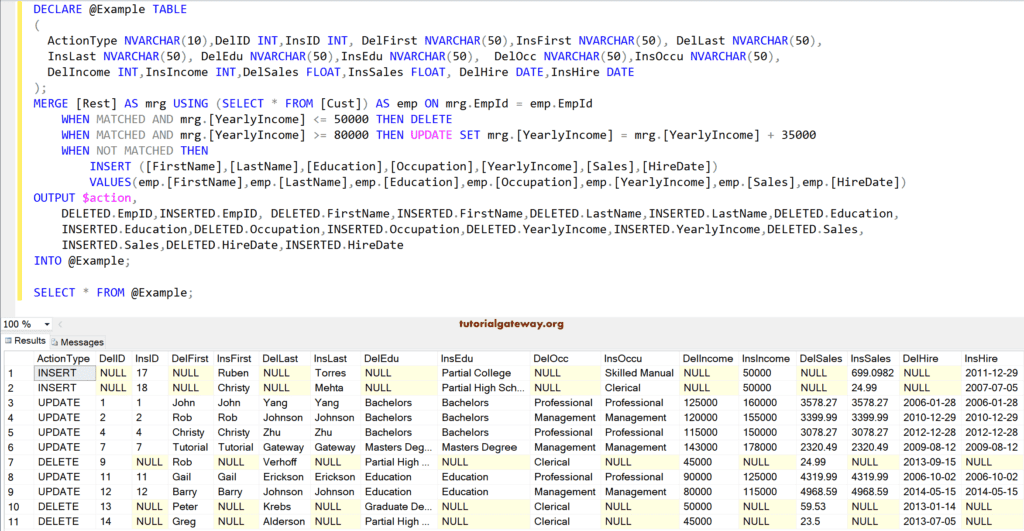
在此 merge 语句示例中,我们声明了表变量 @Example,其中包含代表每列上的删除和插入操作的列。
例如,DelFirstName 用于捕获 [FirstName] 上的删除操作。InsLastName 用于捕获 [LastName] 上的插入操作。请参阅 Delete Statement 文章。
DECLARE @Example TABLE
(
ActionType NVARCHAR(10),
DelID INT,
InsID INT,
DelFirst NVARCHAR(50),
InsFirst NVARCHAR(50),
DelLast NVARCHAR(50),
InsLast NVARCHAR(50),
DelEdu NVARCHAR(50),
InsEdu NVARCHAR(50),
DelOcc NVARCHAR(50),
InsOccu NVARCHAR(50),
DelIncome INT,
InsIncome INT,
DelSales FLOAT,
InsSales FLOAT,
DelHire DATE,
InsHire DATE
);
MERGE [Rest] AS mrg
USING (SELECT * FROM [Cust]) AS emp
ON mrg.EmpId = emp.EmpId
WHEN MATCHED AND mrg.[YearlyIncome] <= 50000 THEN DELETE
WHEN MATCHED AND mrg.[YearlyIncome] >= 80000 THEN
UPDATE SET mrg.[YearlyIncome] = mrg.[YearlyIncome] + 35000
WHEN NOT MATCHED THEN
INSERT ([FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,[Sales]
,[HireDate])
VALUES(emp.[FirstName]
,emp.[LastName]
,emp.[Education]
,emp.[Occupation]
,emp.[YearlyIncome]
,emp.[Sales]
,emp.[HireDate])
OUTPUT $action,
DELETED.EmpID,
INSERTED.EmpID,
DELETED.FirstName,
INSERTED.FirstName,
DELETED.LastName,
INSERTED.LastName,
DELETED.Education,
INSERTED.Education,
DELETED.Occupation,
INSERTED.Occupation,
DELETED.YearlyIncome,
INSERTED.YearlyIncome,
DELETED.Sales,
INSERTED.Sales,
DELETED.HireDate,
INSERTED.HireDate
INTO @Example;
SELECT * FROM @Example;
TOP 子句示例
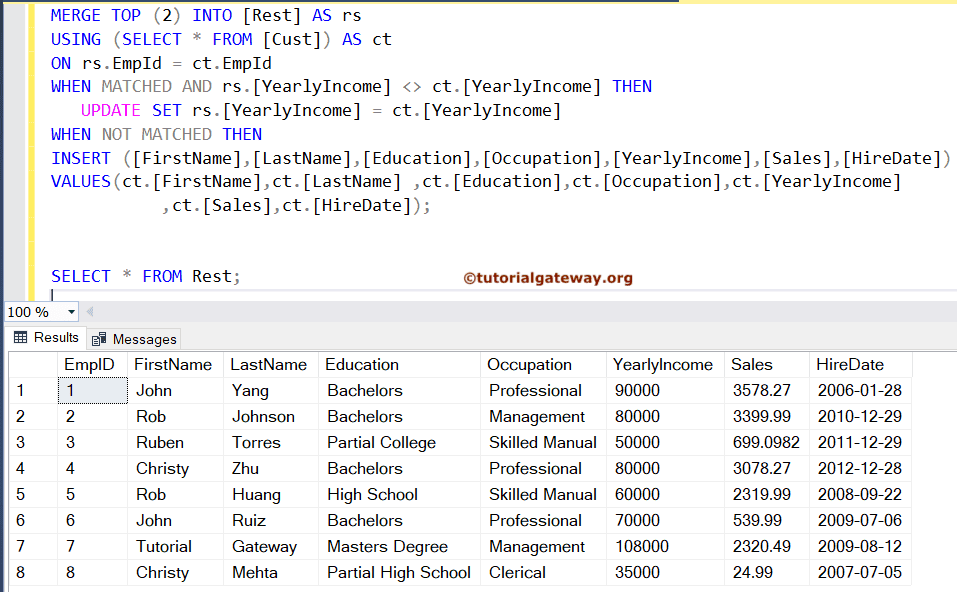
如果查看语法,SQL Server MERGE 语句允许您使用 TOP 子句(指定行数或 PERCENTAGE)分批执行 DML 操作。当您使用 TOP 子句时,首先,查询将连接完整的源表和目标表。接下来,它在上面应用 TOP 子句 来删除不满足数量的行。例如,TOP 20 意味着 MERGE 语句将对这 20 行执行 INSERT、UPDATE 和 DELETE,其余的将被忽略(从查询中移除)。
为了演示 TOP 子句,我们使用了在 INSERT 和 UPDATE 操作示例中使用的相同示例查询。在这里,我们在 MERGE 和 INTO 关键字之间添加了 TOP 2。因此,下面的查询将对前 2 条记录执行 INSERT 和 UPDATE,并忽略其余 6 条记录。通过这种方式,您可以分批执行数据同步。
MERGE TOP (2) INTO [Rest] AS rs
USING (SELECT * FROM [Cust]) AS ct
ON rs.EmpId = ct.EmpId
WHEN MATCHED AND rs.[YearlyIncome] <> ct.[YearlyIncome] THEN
UPDATE SET rs.[YearlyIncome] = ct.[YearlyIncome]
WHEN NOT MATCHED THEN
INSERT ([FirstName],[LastName],[Education],[Occupation],[YearlyIncome],[Sales],[HireDate])
VALUES(ct.[FirstName],ct.[LastName] ,ct.[Education],ct.[Occupation],ct.[YearlyIncome]
,ct.[Sales],ct.[HireDate]);
如果您看到结果,第二条记录的年收入已更新,但保留了第 7 条和第 8 条记录。
SELECT * FROM Rest;
带触发器的 SQL Server MERGE 语句示例
如果目标表上启用了任何 AFTER 触发器,那么服务器将为 MERGE 语句中提到的每个更新、删除或插入操作触发这些触发器。
如果目标表上启用了任何 INSTEAD OF INSERT、UPDATE 或 DELETE 触发器,那么操作将有所不同。它不会删除或更新 target_table,而是触发这些 INSTEAD OF 触发器在定义好的表上执行这些操作。类似地,INSERT 操作会触发 INSTEAD OF INSERT 触发器以将新记录添加到定义的表中(而不是目标表)。
为了演示触发器,我们将为基本示例中所示的 employee(目标)表创建 AFTER INSERT 和 AFTER UPDATE 触发器。接下来,source_employee 是源表。我将创建另一个表来存储审计日志,然后创建触发器。
CREATE TABLE AuditLog (
LogID INT IDENTITY(1,1) PRIMARY KEY,
EmployeeID INT,
Name VARCHAR(100)
ActionType VARCHAR(10),
ChangedAt DATETIME DEFAULT GETDATE()
);
CREATE TRIGGER emp_AuditLog
ON employees
AFTER INSERT, UPDATE
AS
BEGIN
-- Insert Operation
INSERT INTO AuditLog(EmployeeID, Name, ActionType)
SELECT ID, EmployeeName, 'INSERT' FROM inserted
WHERE NOT EXISTS (
SELECT 1 FROM deleted WHERE deleted.ID = inserted.ID)
-- Update Operations
INSERT INTO AuditLog(EmployeeID, Name, ActionType)
SELECT ID, EmployeeName, 'UPDATE' FROM inserted
WHERE EXISTS (
SELECT 1 FROM deleted WHERE deleted.ID = inserted.ID);
END
查询
MERGE INTO employees AS e
USING (SELECT * FROM source_employees) AS st
ON e.ID = st.ID
WHEN MATCHED THEN
UPDATE SET e.Department = st.Department
WHEN NOT MATCHED THEN
INSERT (ID, EmployeeName, Department)
VALUES (st.ID, st.EmployeeName, st.Department);
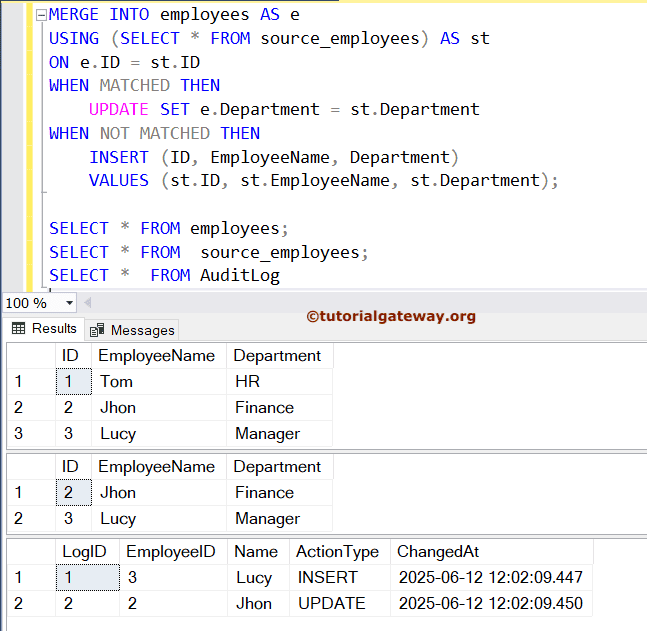
为了避免触发触发器,您可以先禁用这些触发器,然后对目标表执行 MERGE 操作,然后重新启用触发器。下面的代码禁用了触发器。
DISABLE TRIGGER triggerName ON employees;
使用 MERGE 语句执行 UPSERT。接下来,使用下面的代码重新启用触发器。
ENABLE TRIGGER triggerName ON employees;
SQL Server MERGE 语句常见错误:修复!
通过了解 MERGE 语句的常见错误和修复步骤,您可以确保在生产环境中进行顺畅有效的数据同步操作。通过遵循以下建议,您可以避免语法问题、多个源行、重复项等。
多次更新同一行
当有多个或多于一行与目标表匹配(多对一)时,就会发生此错误。为了演示相同,我们使用了在基本示例中创建的 employee 表。接下来,我们截断 source_employees 并插入以下值。如果您查看源,有两个记录的 ID 值均为 2,名称为 Jhon,部门不同。
INSERT INTO source_employees VALUES
(2, 'Jhon', 'Finance'),
(2, 'Jhon', 'Manager');
下面的 SQL MERGE 语句尝试使用源更新 employee 表的 Department 列。由于有两条具有相同 ID 和名称的记录,下面的查询将显示错误。
MERGE INTO employees AS ds
USING (SELECT * FROM source_employees) AS st
ON ds.ID = st.ID
WHEN MATCHED THEN
UPDATE SET ds.Department = st.Department;
Msg 8672, Level 16, State 1, Line 14
The MERGE statement attempted to UPDATE or DELETE the same row more than once. This happens when a target row matches more than one source row. A MERGE statement cannot UPDATE/DELETE the same row of the target table multiple times. Refine the ON clause to ensure a target row matches at most one source row, or use the GROUP BY clause to group the source rows.要修复上述错误,您可以为唯一行使用 DISTINCT 关键字,或者使用 GROUP BY 子句将它们分组。
触发器示例
我将使用相同的示例。下面的触发器将在每次更新 employee 表时触发。如您所知,它将触发两次以更新同一行。
CREATE TRIGGER updateEmployee
ON employees
AFTER UPDATE
AS
BEGIN
-- Some logic to update another table
UPDATE AuditLog
SET EmployeeID = inserted.id
FROM inserted
WHERE AuditLog.EmployeeID = inserted.id;
-- Insert Operation
UPDATE AuditLog
SET ID = inserted.ID FROM inserted
WHERE AuditLog.EmployeeID = inserted.ID
END;
MERGE 语句尝试删除不存在的行
当您尝试从目标表中删除不存在的记录时,会发生此错误。为了演示相同,我们使用了在基本示例中创建的 employee 和 source_employee 表。设想一下,在当前场景中不需要 ID = 3(Lucy),并且我们想将其从目标表中删除。
SQL MERGE 语句将更新 ID 为 2 的一条记录,并尝试检查是否有任何匹配的 Employee ID 可供更新。由于 employee 中没有 ID 为 1 的匹配项,也没有对 ID 为三(不存在)的引用。由于没有 ID 为 1 和 3 的匹配行,两者都将被删除。
MERGE INTO employees AS ds
USING (SELECT * FROM source_employees) AS st
ON ds.ID = st.ID
WHEN MATCHED THEN
UPDATE SET ds.Department = st.Department
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
歧义列引用
当您忘记在 SQL MERGE 语句中使用别名或完全限定的表名来指定特定列属于哪个表时,就会发生此错误。例如,让我使用前面显示的 Rest 和 Cust 表。这里,服务器会混淆 [YearlyIncome] 列,不知道是应该使用 Rest 表还是 Cust 表。因此,它最终会抛出歧义列引用错误。
MERGE [Rest] AS mrg
USING (SELECT * FROM [Cust]) AS emp
ON mrg.EmpId = emp.EmpId
WHEN MATCHED AND mrg.[YearlyIncome] >= 80000 THEN
UPDATE SET [YearlyIncome] = [YearlyIncome] + 35000
Msg 209, Level 16, State 1, Line 5
Ambiguous column name 'YearlyIncome'.要修复上述问题,请将最后的 UPDATE 行替换为以下内容。
UPDATE SET mrg.[YearlyIncome] = mrg.[YearlyIncome] + 35000
处理源表中的 NULL 值
在某些情况下,源表中有 NULL 值,在通过 SQL MERGE 语句进行 UPDATE 时,现有值将被 NULL 值替换。这是您在实际操作中可能会遇到的一个常见场景。如果您的数据包含 NULL 值,而目标表具有正确的值,则必须使用 COALESCE 函数来处理 NULL 值。
为了演示相同,我们使用了 employee 表。接下来,我们截断 source_employees 并插入以下值。
INSERT INTO source_employees VALUES
(2, 'Jhon', NULL),
(3, 'Lucy', 'Manager');
下面的 MERGE 语句尝试更新 ID = 2 并将 ID = 3 插入 employee。如您所见,ID 的部门是 NULL。要解决这些问题,请使用 COALESCE 函数。
MERGE INTO employees AS ds
USING (SELECT * FROM source_employees) AS st
ON ds.ID = st.ID
WHEN MATCHED THEN
UPDATE SET ds.Department = COALESCE(st.Department, ds.Department)
WHEN NOT MATCHED THEN
INSERT (ID, EmployeeName, Department)
VALUES (st.ID, st.EmployeeName, st.Department);
需要考虑的事项
- 尽管 TOP 子句限制了总行数,但 SQL MERGE 语句会扫描源表和目标表的全部内容。因此,查询性能受到影响。
- 批处理操作是好的,但我们必须确保每次都对新批次使用查询。否则,我们将看到不正确的结果。为了避免这种情况,请使用附加的 WHERE 子句,该子句有助于防止更新同一条记录两次等。
评论已关闭。