SQL Server 中的 LEAD 函数是分析函数之一。它允许您在不使用任何自连接或子查询的情况下访问后续行中的数据。当比较当前行和下一行值时,LEAD 函数非常方便。
SQL Server 的 LEAD 函数后面必须跟 ORDER BY 子句和一个可选的 PARTITION BY 子句。ORDER BY 子句根据给定的列以升序或降序对表或分区进行排序,LEAD 函数在该分区内按照该特定顺序检索下一行。
在实际应用中,您可以使用此 LEAD 函数将当前销售额与下一行的销售额进行比较,以识别随时间变化的销售趋势。本文将介绍 SQL Server LEAD 函数的语法、参数和实际示例。
SQL Server LEAD 函数语法
LEAD 函数的基本语法如下所示
SELECT LEAD([Scalar Expression], [Offset], [Default])
OVER (
PARTITION_BY_Clause
ORDER_BY_Clause
)
FROM [Source]
让我们看一下 LEAD 函数的语法参数及其在查询中的意义。
- 标量表达式:请指定您要从中检索连续行值的列名、子查询或表达式。它返回单个值。
- 默认值:这是一个可选参数;您必须在此处指定一个默认值。默认情况下,如果没有后续行,SQL LEAD 函数将返回 NULL。但是,如果您传递了默认值,NULL 将被替换为该值。如果省略 default_value,此函数将写入 NULL。
- 偏移量:一个可选参数,用于确定您要向前查看多少行。例如,偏移量为 1 表示下一行,2 表示选择第 2 行(即下一行的下一行)。同样,它可以是列、子查询或返回单个值的表达式。
- Partition_By_Clause:它允许您根据给定的列将 SELECT 语句选择的表记录分成多个分区。如果您定义了 Partition By Clause,LEAD 函数将绑定到该组并在每个分区中选择后续行。如果您不这样做,LEAD 函数会将所有表记录视为一个分区。
- Order_By_Clause:这是一个必需参数,用于将分区数据按升序或降序排序。请参阅SQL Server 中的 Order By Clause。LEAD 函数根据此顺序返回下一行。
SQL Server LEAD 函数示例
本节涵盖多个示例,以更好地理解 LEAD 函数以及 PARTITION BY 子句如何改变整个结果集。我们还将解释 Offset 和默认值在处理 NULL 值中的重要性。在此 LEAD 函数演示中,我们将使用下面显示的数据。
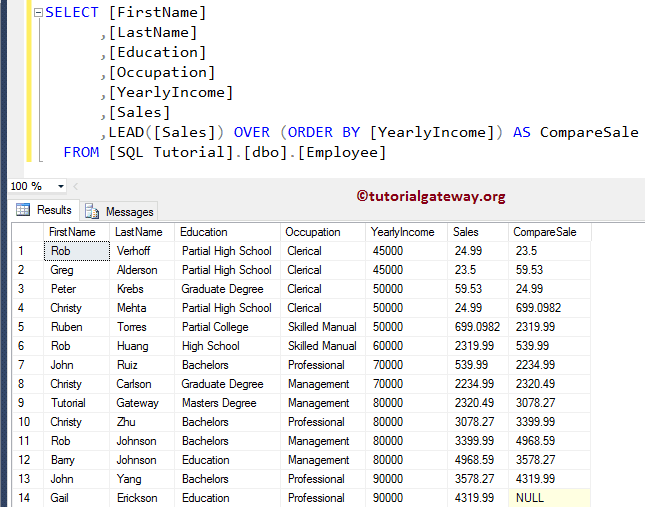
SQL LEAD 函数,无默认值
此示例解释了如果我们省略 LEAD 函数中的 Partition By Clause 和 Default 值会发生什么。
首先,ORDER BY [YearlyIncome] 将根据员工的年收入值升序对 Employee 表进行排序。接下来,SQL Server LEAD 函数将后续行的值(来自行的下一个值)作为输出返回。如果没有要返回的行,它将返回 NULL,因为我们没有定义任何默认值。
SELECT [FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,[Sales]
,LEAD([Sales]) OVER (ORDER BY [YearlyIncome]) AS CompareSale
FROM [Employee]
您可以从下面的图片中看到,Gail Erickson 的 Compare Sale 是 NULL,因为没有下一行且没有默认值。
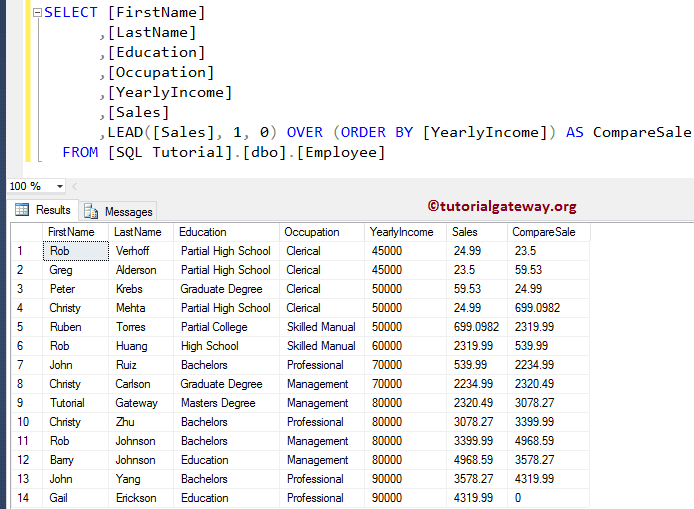
SQL LEAD 函数带默认值以处理 NULL 值
我将修改上面的 LEAD 函数示例,添加 Offset 作为 1,默认值为 0。虽然 Offset 的默认值是 1,但在使用默认值之前必须指定它,因为它是第二个参数。如果省略 Offset 值,0 将成为 Offset,并且没有默认值将替换 NULL。
SELECT [FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,[Sales]
,LEAD([Sales], 1, 0) OVER (
ORDER BY [YearlyIncome]
) AS CompareSale
FROM [Employee]
现在您可以看到 LEAD 函数将 Gail Erickson 的 NULL 值替换为 0。这意味着 Default Value 参数将处理 LEAD 函数返回的 NULL 值。请参阅 LAG Function 和 SELF JOIN 文章。
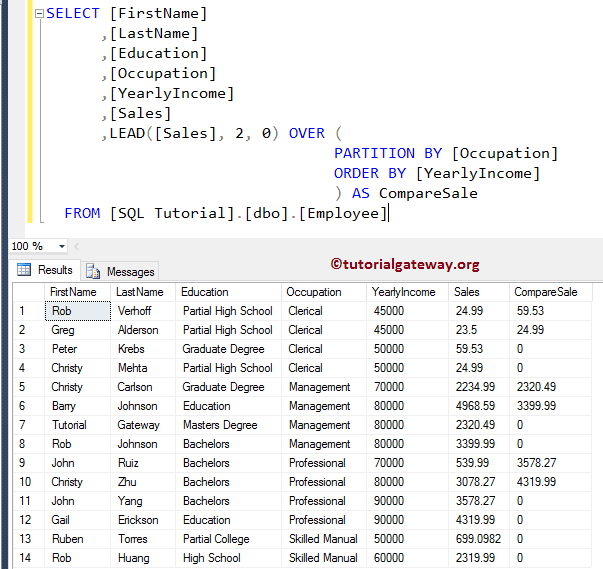
SQL Server LEAD 函数带 Partition By Clause
此示例说明了如何使用 LEAD 函数返回表分区记录中的下一条值。在以上所有示例中,我们都没有使用 PARTITION BY 子句,因此该函数将整个表视为一个分区。当您使用 PARTITION BY 子句时,它会根据给定的列对表记录进行分组。
以下查询将按职业对 Employee 表数据进行分组(分区)。接下来,ORDER BY 子句将根据其年收入值升序对每个分区进行排序。最后,LEAD 函数检索每个分区中的后续销售值。
SELECT [FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,[Sales]
,LEAD([Sales], 1, 0) OVER (
PARTITION BY [Occupation]
ORDER BY [YearlyIncome]
) AS CompareSale
FROM [Employee]
如您所见,对于第四、第八、第十二和第十四行,LEAD 函数返回 0,因为所有这些记录都是其分区的最后一条记录。因此,在该分区内没有后续记录可供选择。
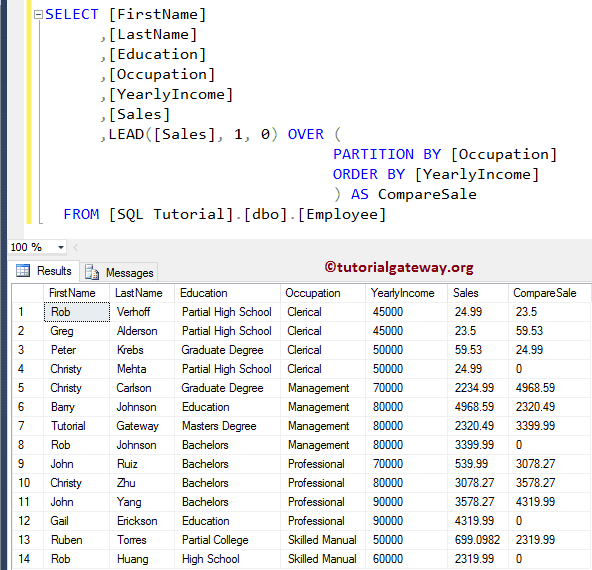
如果省略 Offset 和默认值,这些 0 将被 NULL 替换。为此,请在上面的代码中将 LEAD([Sales], 1, 0) 替换为 LEAD([Sales])。
PARTITION BY 的作用
以上查询说明了带 Partition by 子句的 SQL Server LEAD 函数。它在各个职业组内选择后续行。但是,如果我们更改 PARTITION BY 列,它将返回一个全新的销售值。让我将分区列更改为 Education 以更好地理解。
以下查询返回每个教育组的销售额,而不是职业分区。我希望您能理解。
SELECT [FirstName]
,[LastName]
,[Occupation]
,[Education]
,[YearlyIncome]
,[Sales]
,LEAD([Sales], 1, 0) OVER (
PARTITION BY [Education]
ORDER BY [YearlyIncome]
) AS CompareSale
FROM [Employee]
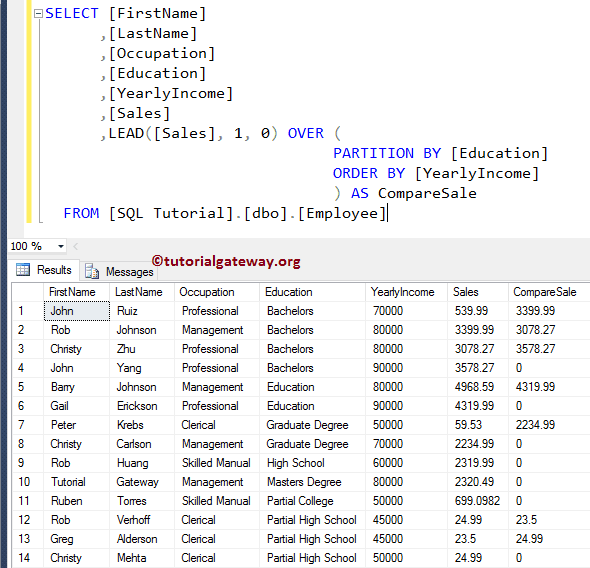
SQL Server LEAD 函数,Offset 值为 2
正如我们之前提到的,默认偏移量是 1。如果我们更改 LEAD 函数的 Offset 值,将默认的 1 更改为 2 会怎样?
SELECT [FirstName]
,[LastName]
,[Education]
,[Occupation]
,[YearlyIncome]
,[Sales]
,LEAD([Sales], 2, 0) OVER (
PARTITION BY [Occupation]
ORDER BY [YearlyIncome]
) AS CompareSale
FROM [Employee]
如果您观察下面的截图,LEAD 函数将选择第 2 行(跳过一行),而不是下一行。如果您将值更改为 3,它将跳过前两行并选择第三行,依此类推。
Skilled Manual 组只有两行。对于 Ruben Torres,它尝试通过跳过第 14 行来检索第 2 行(第 15 行)。第 15 行没有记录,因此它返回默认的 0。