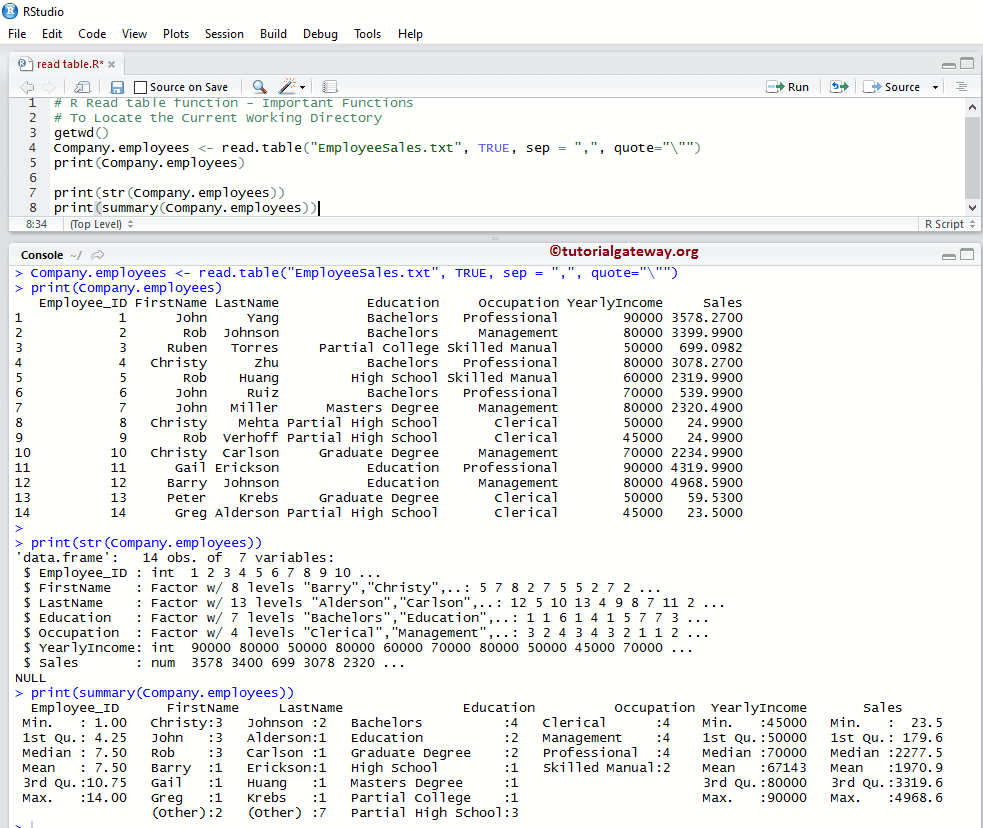
R 的 read.table 函数非常有用,可以从文件系统和 URL 导入文本文件数据,并将数据存储在数据框(Data Frame)中。让我们通过一个示例,在编程中了解如何使用此 read table 函数并操作数据。
R 读取表语法
R read.table 函数从文本文件读取数据的语法是:
read.table(file, header = FALSE, sep = "", quote = "\"'", dec = ".",
row.names, col.names, na.strings = "NA", nrows = -1, skip = 0,
numerals = c("allow.loss", "warn.loss", "no.loss"), colClasses = NA,
as.is = !stringsFactors, check.names = TRUE, strip.white = FALSE,
fill = !blank.lines.skip, blank.lines.skip = TRUE, comment.char = "#",
allowEscapes = FALSE, flush = FALSE, fileEncoding = "", text,
stringsAsFactors = default.stringsAsFactors(), encoding = "unknown",
skipNul = FALSE)
R 编程语言中的 read.table 支持的参数列表是:
- dec:指定用于小数点的字符。
- check.names:请指定您是否要检查 R 编程中的列名是否有效。
- row.names:一个字符向量,其中包含返回的数据框的行名。
- nrows:这是一个整数值。您可以使用此参数限制要读取的行数。例如,如果您想要前 5 条记录,请在 read table 函数中使用 nrows = 5。
- colClasss:一个字符向量,包含分配给每个列的类名。
- fill:有时,我们可能会遇到文件中的行长度不相等的情况,我们需要为那些缺失的值添加空白。
- flush:在读取完一行中所有请求的字段后,如果您希望 read.table 跳到下一行,则可以使用此布尔值参数。
- encoding:如果存在任何编码方案,请指定用于源文件的方案。默认值为“unknown”。
下面的屏幕截图显示了我们的 EmployeeSales.txt 文件中的数据,我们将使用此文件来演示 R read.table 函数。您可以看到它有列名、14 行和 7 列。
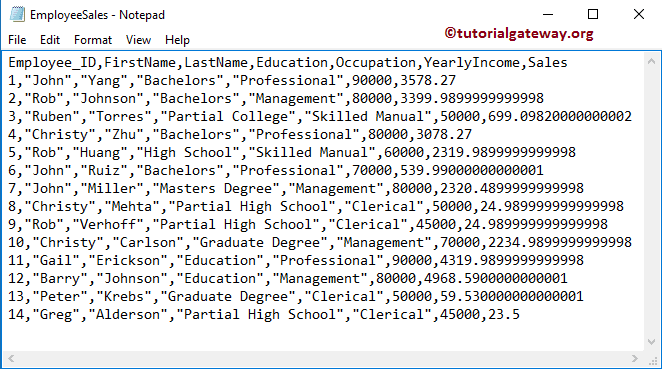
如果您想使用相同的数据,请将以下数据复制并粘贴到记事本中,然后将其保存为 EmployeeSales.txt。
Employee_ID,FirstName,LastName,Education,Occupation,YearlyIncome,Sales 1,"John","Yang","Bachelors","Professional",90000,3578.27 2,"Rob","Johnson","Bachelors","Management",80000,3399.9899999999998 3,"Ruben","Torres","Partial College","Skilled Manual",50000,699.09820000000002 4,"Christy","Zhu","Bachelors","Professional",80000,3078.27 5,"Rob","Huang","High School","Skilled Manual",60000,2319.9899999999998 6,"John","Ruiz","Bachelors","Professional",70000,539.99000000000001 7,"John","Miller","Masters Degree","Management",80000,2320.4899999999998 8,"Christy","Mehta","Partial High School","Clerical",50000,24.989999999999998 9,"Rob","Verhoff","Partial High School","Clerical",45000,24.989999999999998 10,"Christy","Carlson","Graduate Degree","Management",70000,2234.9899999999998 11,"Gail","Erickson","Education","Professional",90000,4319.9899999999998 12,"Barry","Johnson","Education","Management",80000,4968.5900000000001 13,"Peter","Krebs","Graduate Degree","Clerical",50000,59.530000000000001 14,"Greg","Alderson","Partial High School","Clerical",45000,23.5
R 读取表以读取当前目录下的文本文件
在此示例中,我们展示了如何使用 read.table 函数读取当前工作目录中存在的文本文件(.txt 文件)的数据。
- file:您必须指定文件名或包含文件名的完整路径。您也可以使用外部(在线)txt 文件的 URL。例如,sampleFile.txt “C:/Users /Suresh /Documents /R Programs /sampleFile.txt”。
- header:如果文本文件包含第一行作为列名,请指定 TRUE,否则指定 FALSE。
- sep:它是 separator 的缩写。您必须指定分隔字段的字符。“,”表示数据由逗号分隔。
- quote:如果您的字符值(如 LastName、Occupation、Education 列等)用引号括起来,那么您必须指定引号类型。对于双引号,我们使用:quote = “\””。
# Read Text File from Current Working Directory
# To Locate the Current Working Directory
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(Company.employees)
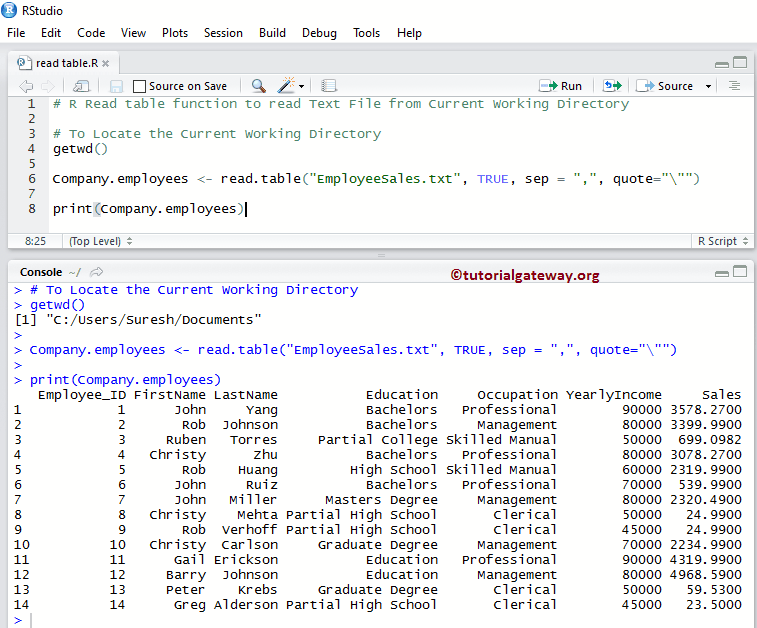
R 读取表以读取自定义目录下的文本文件
在此示例中,我们使用 read.table 函数读取自定义目录中存在的文本文件的数据。
- getwd():这个 R 编程方法返回当前工作目录。大多数情况下,它是您的 Documents 文件夹。
- setwd(“system address”):此方法可以帮助我们根据您的要求更改当前目录。
- list.files():此方法显示该目录中存在的文件列表。
# Read Text File from Custom Working Directory
# To Locate the Current Working Directory
getwd()
setwd("R Programs") # Or use Full path C:/Users/Suresh/Documents/R Programs
list.files()
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(Company.employees)
参数
以下屏幕截图显示了我们修改后的 EmployeeSales.txt 文件中的数据。在这里,我们将使用此文件来演示 R read.table 函数中的参数。您可以看到,它包含一些空行、空记录和注释行。
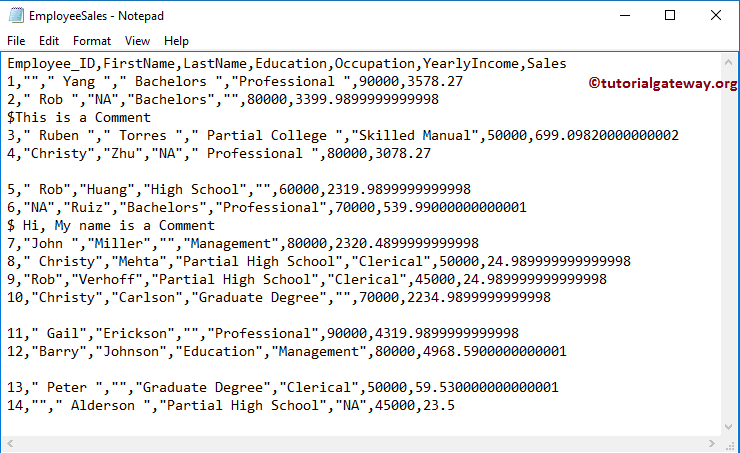
R 读取表函数测试参数
在此 read table 示例中,我们展示了如何在读取文本文件数据时读取 NA 记录、转义空白行和注释行。
- allowEscapes:一个布尔值,指示您是否要允许转义(如 \n 表示换行符)。
- strip.white:如果 sep 参数不等于“”,则您可以使用此布尔值来修剪字符字段中多余的前导和尾随空格。
- comment.char:如果您的文本文件中包含任何注释行,则可以使用此参数忽略这些行。在这里,您必须描述用于注释行的单个特殊字符。例如,如果您的文本文件以 $ 开头的注释,则使用 comment.char = “$” 来跳过此注释行,而不进行读取。
- blank.lines.skip:一个布尔值,指定您是否要跳过/忽略空白行。
- na.strings:一个字符向量,指定读取为 NA 的值。
# Testing argument
# To Locate the Current Working Directory
getwd()
employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"",
na.strings = TRUE, strip.white = TRUE,
comment.char = "$",blank.lines.skip = TRUE)
print(employees)
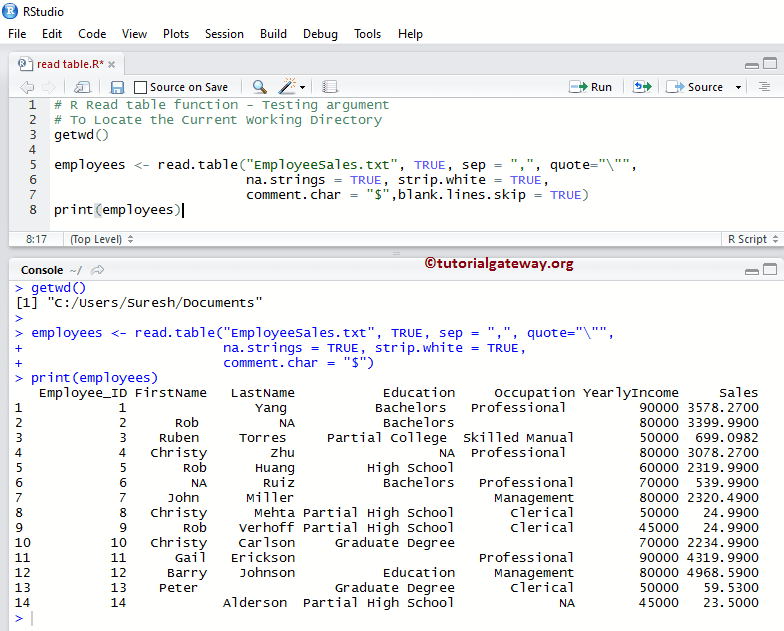
测试 R 读取表参数
在此示例中,我们展示了如何重命名列名、跳过行数以及更改默认的因子。
- col.names:一个字符向量,其中包含返回的数据框的列名。
- as.is:请指定一个布尔向量,其长度与列数相同。此参数根据布尔值将字符值转换为因子。例如,我们有两个列(FirstName、Occupation),我们使用 as.is = c(TRUE, FALSE)。它将 FirstName 保持为字符(而不是隐式因子),将 Occupation 保持为因子。
- skip:请指定在开始读取数据之前要从文本文件中跳过的行数。例如,如果您想跳过前 3 条记录,请使用 skip = 3。
# Testing argument
# To Locate the Current Working Directory
getwd()
employeeNames <- c("Employee_ID", "First Name", "Last Name", "Education", "Profession","Salary","Sales")
employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"",
na.strings = TRUE, strip.white = TRUE, skip = 3,
as.is = c(TRUE, TRUE, FALSE, FALSE, TRUE),
col.names = employeeNames,
comment.char = "$", blank.lines.skip = TRUE)
print(employees)
print(str(employees))
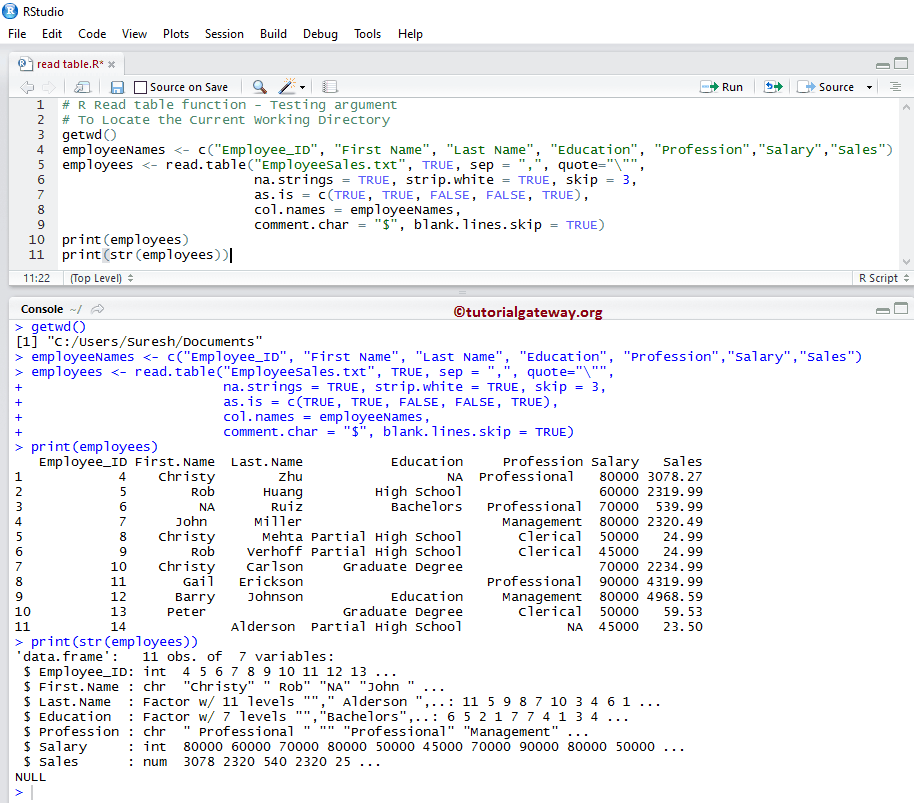
R read.table 函数中的 stringsAsFactors
如果您的文本文件同时包含字符和数值变量,那么字符变量会自动转换为因子类型。为了防止这种自动转换,我们必须显式指定 stringsAsFactors = FALSE。
- stringsAsFactors:一个布尔值,指示 .txt 文件中的文本字段是否转换为因子。默认值为 default.stringsAsFactors()。
# stringsAsFactors argument
# To Locate the Current Working Directory
getwd()
# It will keep the Character Columns as it is
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"",
stringsAsFactors = FALSE)
# It will Implicitly convert all the Character Columns to factors
employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(str(Company.employees))
print(str(employees))
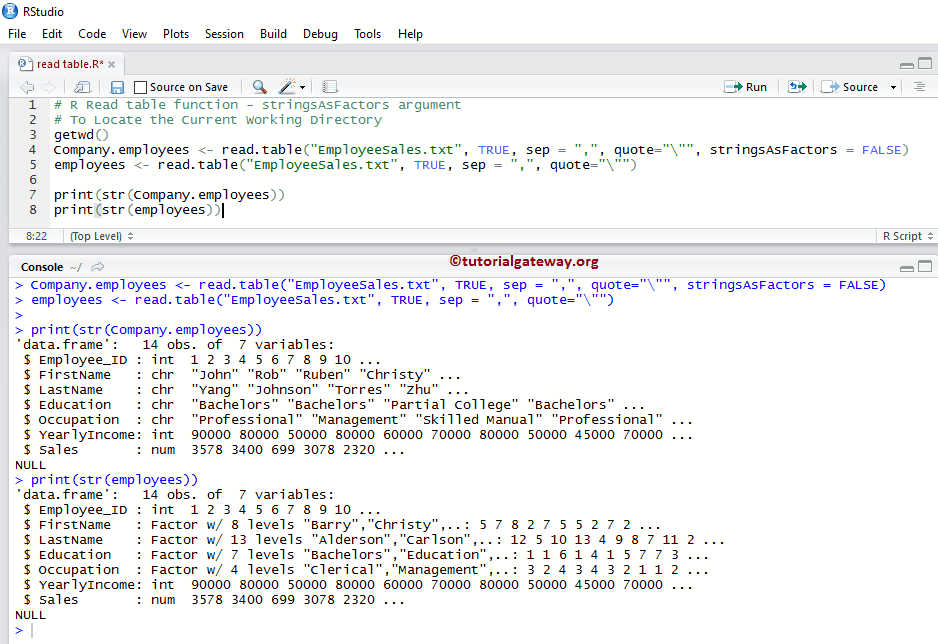
访问文本文件数据
R 编程中的 read.table 会自动将数据转换为数据框。因此,数据框支持的所有函数都可用于文本数据。请参考 Data Frame 文章以了解函数的描述。
# Access Data
# To Locate the Current Working Directory
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(Company.employees)
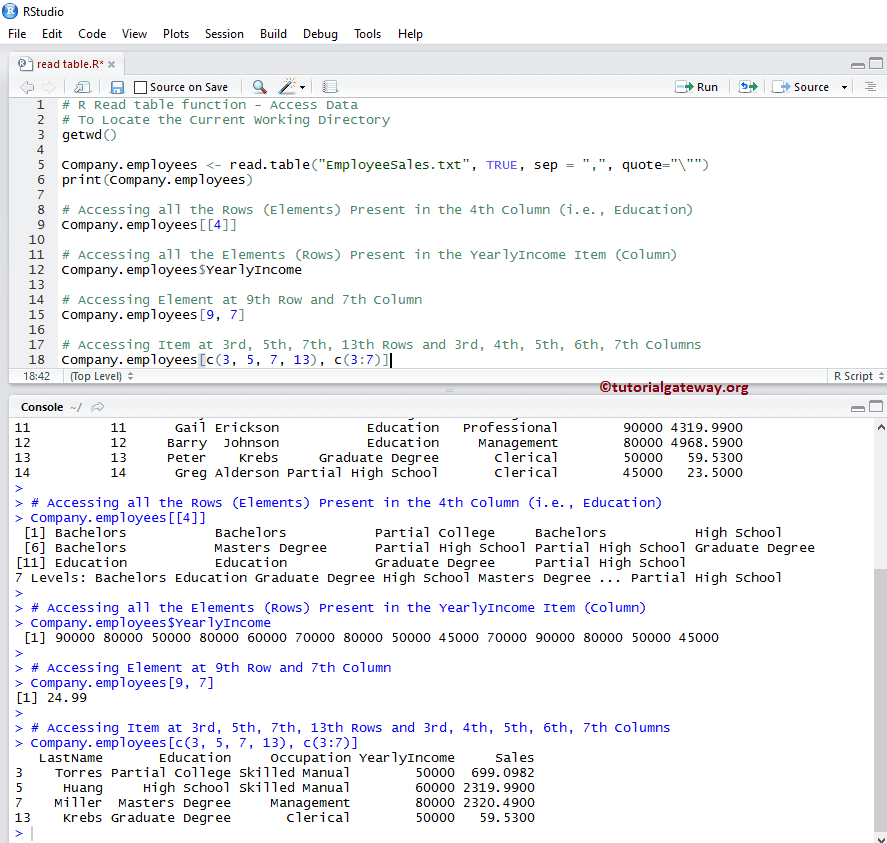
# Accessing all the Rows (Elements) Present in the 4th Column (i.e., Education)
#Index Values: 1 = Employee_ID, 2 = FirstNmae, 3 = LastName, 4 = Education, 5 = Occupation, 6 = Yearly Income, and 7 = Salary
Company.employees[[4]]
# Accessing all the Elements (Rows) Present in the YearlyIncome Item (Column)
Company.employees$YearlyIncome
# Accessing Element at 9th Row and 7th Column
Company.employees[9, 7]
# Accessing Item at 3rd, 5th, 7th, 13th Rows and 3rd, 4th, 5th, 6th, 7th Columns
Company.employees[c(3, 5, 7, 13), c(3:7)]
R read.table 的常用函数
在 R 编程中处理文本文件时,以下函数是最常用的函数。
- max:此方法返回列中的最大值。
- min:此方法返回列中的最小值。
- mean:它计算平均值。
- median:它计算指定列的中值。
- subset(data, condition):此方法返回数据的子集,数据取决于条件。
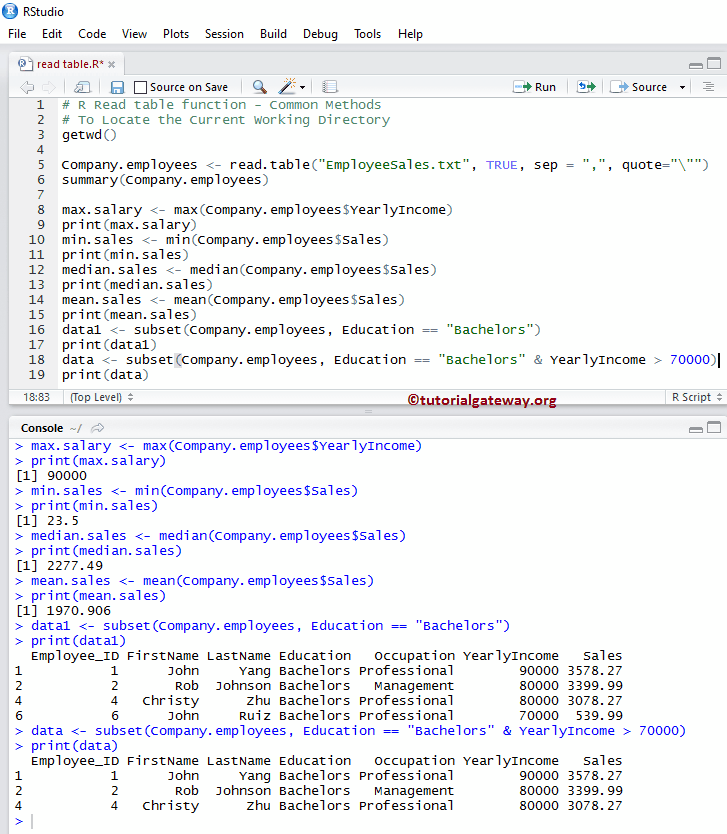
# Common Methods
# To Locate the Current Working Directory
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
summary(Company.employees)
# It returns the Maximum Value present in the Yearly Income Column
max.salary <- max(Company.employees$YearlyIncome)
print(max.salary)
# It returns the Minimum Value present in the Sales Column
min.sales <- min(Company.employees$Sales)
print(min.sales)
# It will calculate and returns the Median of Sales Column
median.sales <- median(Company.employees$Sales)
print(median.sales)
# It will calculate and returns the Mean value of Sales Column
mean.sales <- mean(Company.employees$Sales)
print(mean.sales)
# It will returns all the records, whose Education is equal to Bachelors
data1 <- subset(Company.employees, Education == "Bachelors")
print(data1)
# It will return all the records, whose Education is equal to Bachelors and Yearly Income > 70000
data <- subset(Company.employees, Education == "Bachelors" & YearlyIncome > 70000)
print(data)
R 读取文本文件中的 Head 和 Tail 函数
下面 R 编程中的 read table 函数是处理外部数据(文本文件)非常有用的函数。如果您的文本文件有数百万条记录,并且您想提取表现最好和最差的记录(前 10 条、后 10 条记录),那么请使用这些函数。
- head(Data Frame, limit):此方法返回前六个元素(如果您省略 limit)。如果您将 limit 指定为 3,它将返回前三条记录。这就像选择前 20 条记录。
- tail(Data Frame, limit):它返回最后六个元素(如果您省略 limit)。如果您将 limit 指定为 4,则返回最后四条记录。这就像选择后 10 条记录。
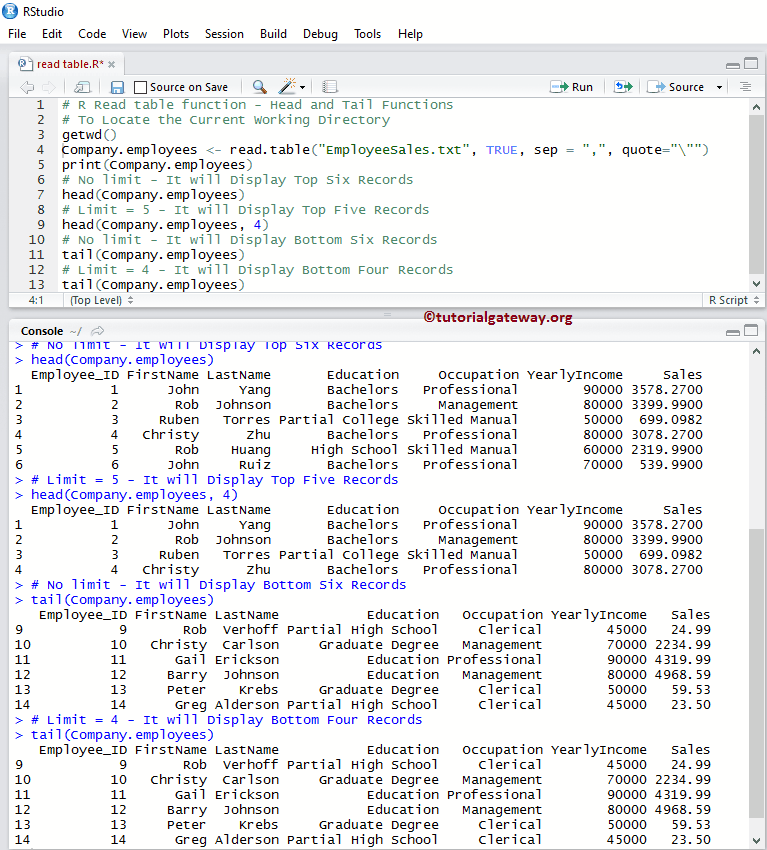
# Head and Tail Functions
# To Locate the Current Working Directory
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(Company.employees)
# No limit - It will Display Top Six Records
head(Company.employees)
# Limit = 5 - It will Display Top Five Records
head(Company.employees, 4)Head and Tail Functions
# No limit - It will Display Bottom Six Records
tail(Company.employees)
# Limit = 4 - It will Display Bottom Four Records
tail(Company.employees)
读取文本文件的重要函数
在 R 编程中处理或读取文本文件时,以下函数是最有用的函数。
- typeof:此方法告诉您变量的类型。由于数据框是一种列表,因此此函数返回一个列表。
- class:此方法告诉您文本文件中的数据的类。
- names:它返回列名。
- length:此方法计算文本文件中的项目(列)数。
- dim:它返回文本文件中的总行数和列数。
- nrow:此方法返回文本文件中的行数。
- ncol:它返回文本文件中的总列数。
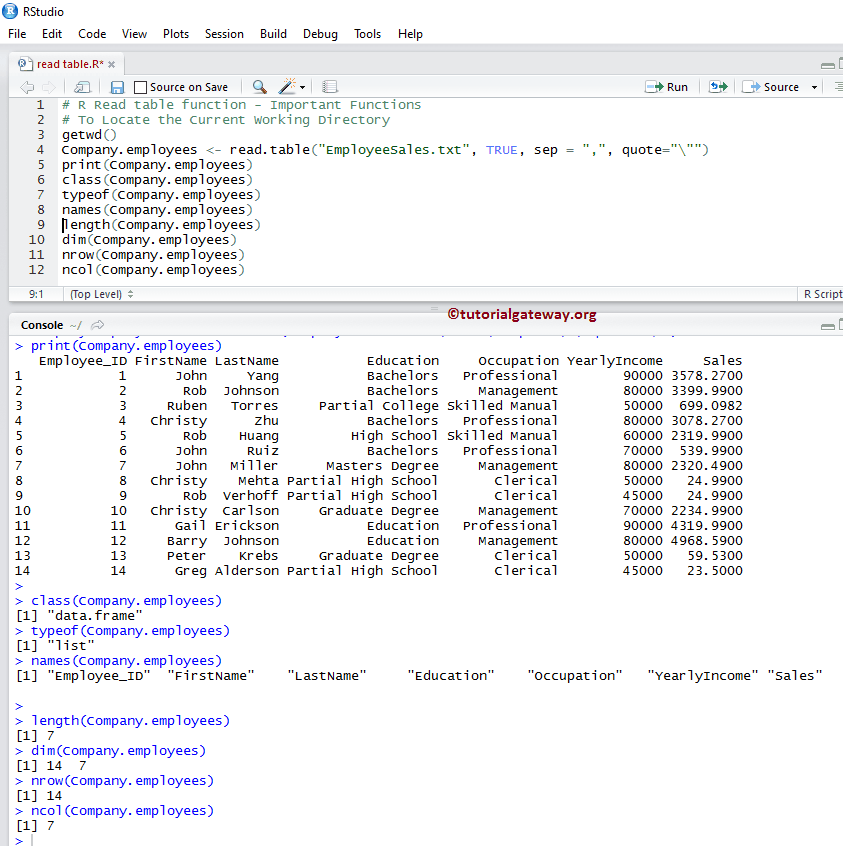
# Important Functions
# To Locate the Current Working Directory
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(Company.employees)
class(Company.employees)
typeof(Company.employees)
names(Company.employees)
length(Company.employees)
dim(Company.employees)
nrow(Company.employees)
ncol(Company.employees)
特殊函数
以下两个函数是 R 编程中 read table 函数支持的非常有用的函数。在开始操作或插入新记录之前,检查外部数据的结构总是一个好主意。
- summary(Data Frame):它返回外部数据的性质和统计摘要,如最小值、中位数、平均值、中位数等。
- str(Data Frame):这个 read table 函数返回文本文件中的数据结构。
# Important Functions
# To Locate the Current Working Directory
getwd()
Company.employees <- read.table("EmployeeSales.txt", TRUE, sep = ",", quote="\"")
print(Company.employees)
print(str(Company.employees))
print(summary(Company.employees))