Python 中的 Pandas DataFrame 是一种二维数据结构。这意味着数据框以表格形式(即行和列)存储数据。
本文将展示如何创建 DataFrame,以及如何访问和修改行和列。接下来,我们将讨论库中的转置 DataFrame、迭代行等。
如何在 Python 中创建 pandas DataFrame?
在实时应用中,我们使用这个 Python Pandas DataFrame 从 SQL Server、文本文件、Excel 文件或任何 CSV 文件加载数据。然后,我们根据需要对数据进行切片和切块。最后,一旦数据达到我们所需的格式,我们就使用这些数据通过 matplotlib 模块创建报告、图表或图形。
在 Python pandas 中创建空 DataFrame
这是一个创建空 DataFrame 的简单示例。在这里,我们创建一个空的 DataFrame。
import pandas as pd data = pd.DataFrame() print(data)
创建空 DataFrame 输出
Columns: []
Index: []从列表创建 Python pandas DataFrame
在这里,我们创建了一个整数值列表。然后,我们使用 DataFrame 函数从列表中创建我们的 df,或将列表转换。
table = [1, 2, 3, 4, 5] data = pd.DataFrame(table) print(data)
0
0 1
1 2
2 3
3 4
4 5从混合列表创建或将混合列表转换为 Pandas Data Frame。在这里,我们也使用了多行和多列。
mixedtable = [[1, 'Suresh'], [2, 'Python'], [3, 'Hello']] mixeddata = pd.DataFrame(mixedtable) print(mixeddata)
我们必须使用 columns 参数为列值指定名称。例如,以下代码为列提供了名称,而不是 1 和 2。
mixdata = pd.DataFrame(mixedtable, columns = ['S.No', 'Name']) print(mixdata)
0 1
0 1 Suresh
1 2 Python
2 3 Hello
# WIth Names Output
S.No Name
0 1 Suresh
1 2 Python
2 3 Hello随机数的 Python pandas DataFrame
为了使用随机数创建 DataFrame,我们使用了 numpy 随机函数来生成大小为 8 * 4 的随机数。然后,我们使用该函数将这些序列转换为 DataFrame。
import numpy as np import pandas as pd d_frame = pd.DataFrame(np.random.randn(8, 4)) print(d_frame)
0 1 2 3
0 -0.492116 -0.824771 -0.869890 -1.753722
1 -0.733930 0.947616 0.089861 0.888474
2 -0.948483 -1.002449 -0.283761 -0.207897
3 0.013346 2.059951 1.064830 0.830474
4 0.289157 -0.418271 -0.770464 0.223895
5 -0.781827 -0.396441 0.123848 -0.824002
6 0.667090 0.183589 1.212163 0.231251
7 1.067570 -0.615639 0.461147 -1.365541来自 dict 的 Python Pandas DataFrame
它允许您从 dict 或字典创建 DataFrame。这非常直接。您所要做的就是声明一个包含不同值的字典,然后使用该函数将该字典转换为 DataFrame。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table)
print(data)
要从 dict 创建 df,所有字典值应与所有键的长度相同。否则,它会引发错误。接下来,如果您传递索引值,它们应与键值或数组的长度匹配;否则,它会引发错误。最后,如果您没有传递任何索引值,它将自动为您创建索引,从 0 到 n-1。
name Salary
0 John 1000000
1 Mike 1200000
2 Suresh 900000
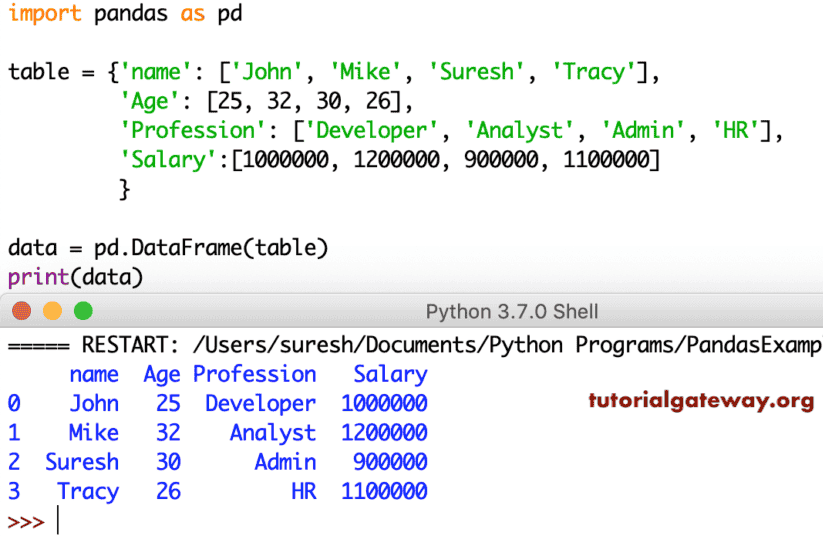
3 Tracy 1100000让我再举一个从字典创建 DataFrame 的例子。这次,我们正在转换四列数据的 Python 字典键。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table)
print(data)
如何从列表字典创建 Python pandas DataFrame
如果您对将所有内容放在一个地方感到困惑,请将其分成几部分。在这里,我们声明了四个项目列表,并为每个列分配了它们。
names = ['John', 'Mike', 'Suresh', 'Tracy']
ages = [25, 32, 30, 26]
Professions = ['Developer', 'Analyst', 'Admin', 'HR']
Salaries = [1000000, 1200000, 900000, 1100000]
table = {'name': names,
'Age': ages,
'Profession': Professions,
'Salary': Salaries
}
data = pd.DataFrame(table)
print(data)
name Age Profession Salary
0 John 25 Developer 1000000
1 Mike 32 Analyst 1200000
2 Suresh 30 Admin 900000
3 Tracy 26 HR 1100000日期的 DataFrame
您还可以使用此模块创建一系列日期的 DataFrame。例如,让我创建一个包含 2019-01-01 到 2019-01-08 日期的 DataFrame。通过更改 period 值,您可以生成更多日期序列。
dates = pd.date_range('20190101', periods = 8)
print(dates)
print()
d_frame = pd.DataFrame(np.random.randn(8, 4), index = dates,
columns = {'apples', 'oranges', 'kiwis', 'bananas'})
print(d_frame)
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07', '2019-01-08'],
dtype='datetime64[ns]', freq='D')
kiwis apples oranges bananas
2019-01-01 -0.393538 -0.406943 1.612431 1.089230
2019-01-02 1.070080 -1.565538 0.727056 1.677534
2019-01-03 -1.324169 0.256827 1.332544 -2.952971
2019-01-04 0.419778 -0.562119 0.507846 -0.223730
2019-01-05 0.175785 1.566511 -1.832633 2.035536
2019-01-06 0.541516 -0.113477 0.444046 0.387718
2019-01-07 0.247760 -1.143530 0.615681 0.400743
2019-01-08 -0.242328 0.913758 -0.088591 -0.533690Python pandas DataFrame 列
此示例显示了如何重新排序列。默认情况下,数据框将使用我们在实际数据中使用的列顺序。但是,您可以使用此参数更改任何列的位置。例如,让我将 Age 从第二个位置更改为第四个位置。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table)
print(data)
print('\n---- After Changing the Order-----')
data2 = pd.DataFrame(table, columns = ['name', 'Profession', 'Salary', 'Age'])
print(data2)
使用此列参数时请小心。如果我们指定,任何不存在的列名或拼写错误都将返回 NaN。让我使用 Qualification 列名(它不存在)
print('\n---- Using Wrong Col -----')
data3 = pd.DataFrame(table, columns = ['name', 'Qualification', 'Salary', 'Age'])
print(data3)
columns 属性以相同的顺序和数据类型返回数据框中可用列的列表。
print(data.columns) print(data2.columns) print(data3.columns)
输出
name Age Profession Salary
0 John 25 Developer 1000000
1 Mike 32 Analyst 1200000
2 Suresh 30 Admin 900000
3 Tracy 26 HR 1100000
---- After Changing the Order-----
name Profession Salary Age
0 John Developer 1000000 25
1 Mike Analyst 1200000 32
2 Suresh Admin 900000 30
3 Tracy HR 1100000 26
---- Using Wrong Col -----
name Qualification Salary Age
0 John NaN 1000000 25
1 Mike NaN 1200000 32
2 Suresh NaN 900000 30
3 Tracy NaN 1100000 26
Index(['name', 'Age', 'Profession', 'Salary'], dtype='object')
Index(['name', 'Profession', 'Salary', 'Age'], dtype='object')
Index(['name', 'Qualification', 'Salary', 'Age'], dtype='object')Python Pandas DataFrame 索引
默认情况下,它将索引值从 0 分配到 n-1,其中 n 是最大数量。但是,您可以使用 index 属性更改这些默认索引值。在这里,我们使用相同的并分配从 a 到 d 的字母作为索引值,而不是 0 到 N – 1。
# Index Values are a, b, c, d
data2 = pd.DataFrame(table, index = ['a', 'b', 'c', 'd'])
print('\n----After Setting Index Values----')
print(data2)
您可以使用 set_index 函数更改或设置列作为索引值。在这里,我们使用这个 set_index 函数,而不是将名称设置为索引。接下来,loc 函数显示我们可以使用索引名称获取额外信息。
print('\n---Setting name as an index---')
new_data = data.set_index('name')
print(new_data)
print('\n---Return Index John Details---')
print(new_data.loc['John'])
----After Setting Index Values----
name Age Profession Salary
a John 25 Developer 1000000
b Mike 32 Analyst 1200000
c Suresh 30 Admin 900000
d Tracy 26 HR 1100000
---Setting name as an index---
Age Profession Salary
name
John 25 Developer 1000000
Mike 32 Analyst 1200000
Suresh 30 Admin 900000
Tracy 26 HR 1100000
---Return Index John Details---
Age 25
Profession Developer
Salary 1000000
Name: John, dtype: objectDataFrame 属性
Python DataFrame 中可用的 pandas 属性列表。
DataFrame shape 属性
Pandas shape 属性返回其中行数和列数的形状或元组。
import pandas as pd
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table)
print('\n---Shape or Size ---')
print(data.shape)
---Shape or Size ---
(4, 3)DataFrame values 属性
values 属性以二维数组格式返回数据(不带列名)。
data2 = pd.DataFrame(table, columns = ['name', 'Profession', 'Salary', 'Age'])
data3 = pd.DataFrame(table, columns = ['name', 'Qualification', 'Salary', 'Age'])
print('---Data2 Values--- ')
print(data2.values)
print('\n---Data3 Values--- ')
print(data3.values)
---Data2 Values---
[['John' 'Developer' 1000000 25]
['Mike' 'Analyst' 1200000 32]
['Suresh' 'Admin' 900000 30]
['Tracy' 'HR' 1100000 26]]
---Data3 Values---
[['John' nan 1000000 25]
['Mike' nan 1200000 32]
['Suresh' nan 900000 30]
['Tracy' nan 1100000 26]]上面的示例返回类型为 Object 的数组,因为这两个数据框都包含混合内容(int、string)。如果不是这种情况,它不会在数组中显示任何 dtype。为此,我们使用了整数数据框。
table = {'Age': [25, 32, 30, 26],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data4 = pd.DataFrame(table)
print(data4.values)
[[ 25 1000000]
[ 32 1200000]
[ 30 900000]
[ 26 1100000]]DataFrame name 属性
DataFrame 索引和列都有一个 name 属性,它允许为索引或列分配名称。同样,我们可以使用 Python pandas DataFrame 的列标签属性来为列标题分配名称。
data.index.name = 'Emp No' print(data) print() data4.index.name = 'Cust No' print(data4) # Assign a Name for Column Headers data.columns.name = 'Employee Details' print(data) data4.columns.name = 'Customers Information' print(data4)
name Age Profession Salary
Emp No
0 John 25 Developer 1000000
1 Mike 32 Analyst 1200000
2 Suresh 30 Admin 900000
3 Tracy 26 HR 1100000
Age Salary
Cust No
0 25 1000000
1 32 1200000
2 30 900000
3 26 1100000
# Assign a Name for Column Headers
Employee Details name Age Profession Salary
Emp No
0 John 25 Developer 1000000
1 Mike 32 Analyst 1200000
2 Suresh 30 Admin 900000
3 Tracy 26 HR 1100000
Customers Information Age Salary
Cust No
0 25 1000000
1 32 1200000
2 30 900000
3 26 1100000DataFrame dtype 属性
dtype 属性返回数据结构中每个列的数据类型。
print('\n---dtype attribute result---')
print(data.dtypes)
dtype 属性输出
---dtype attribute result---
name object
Age int64
Profession object
Salary int64
dtype: objectDataFrame describe 函数
使用此 describe 函数可以快速获取有关它的统计信息。
print('\n---describe function result---')
print(data.describe())
describe 函数输出
---describe function result---
Age Salary
count 4.000000 4.000000e+00
mean 28.250000 1.050000e+06
std 3.304038 1.290994e+05
min 25.000000 9.000000e+05
25% 25.750000 9.750000e+05
50% 28.000000 1.050000e+06
75% 30.500000 1.125000e+06
max 32.000000 1.200000e+06如何访问 Python pandas DataFrame 数据?
DataFrame 中的数据以行和列的表格格式存储。这意味着您可以使用列和行访问项目。
访问 DataFrame 列
您可以通过两种方式访问列:在 [] 中或在点表示法后指定列名。这两种方法都将指定列作为 Series 返回。
print('\n-----Accessing Columns-----')
print(data.Age)
print(data['name'])
print(data2.Salary)
# We can also access multiple columns
print('\n-----Accessing Multiple Cols-----')
print(data[['Age', 'Profession']])
print(data2[['name', 'Salary']])
-----Accessing Columns-----
0 25
1 32
2 30
3 26
Name: Age, dtype: int64
0 John
1 Mike
2 Suresh
3 Tracy
Name: name, dtype: object
0 1000000
1 1200000
2 900000
3 1100000
Name: Salary, dtype: int64
-----Accessing Multiple Cols-----
Age Profession
0 25 Developer
1 32 Analyst
2 30 Admin
3 26 HR
name Salary
0 John 1000000
1 Mike 1200000
2 Suresh 900000
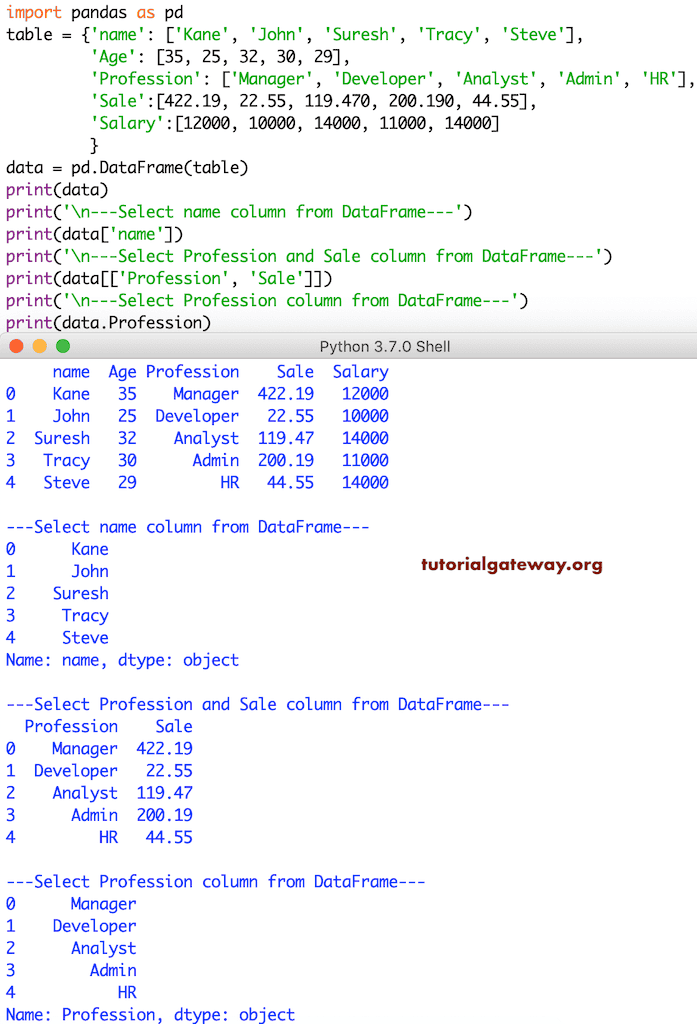
3 Tracy 1100000这是访问列的另一个示例。
table = {'name': ['Kane', 'John', 'Suresh', 'Tracy', 'Steve'],
'Age': [35, 25, 32, 30, 29],
'Profession': ['Manager', 'Developer', 'Analyst', 'Admin', 'HR'],
'Sale':[422.19, 22.55, 119.470, 200.190, 44.55],
'Salary':[12000, 10000, 14000, 11000, 14000]
}
data = pd.DataFrame(table)
print('\n---Select name column ---')
print(data['name'])
print('\n---Select Profession and Sale column ---')
print(data[['Profession', 'Sale']])
print('\n---Select Profession column ---')
print(data.Profession)
访问 DataFrame 行
Python 中的 Pandas DataFrame 也可以使用行访问。在这里,我们使用索引切片技术返回所需的行。在这里,data[1:] 返回数据结构中从索引 1 到 n-1 的所有记录,data[1:3] 返回从索引 1 到 3 的行。
table = {'Fullname': ['Kane', 'John', 'Suresh', 'Tracy', 'Steve'],
'Age': [35, 25, 32, 30, 29],
'Designation': ['Manager', 'Developer', 'Analyst', 'Admin', 'HR'],
'SaleAmount':[422.19, 22.55, 119.470, 200.190, 44.55],
'Income':[12000, 10000, 14000, 11000, 14000]
}
data = pd.DataFrame(table)
#print(data)
print('\n---Select all rows from 1 to N ---')
print(data[1:])
print('\n---Select rows from 1 to 2 ---')
print(data[1:3])
print('\n---Select rows from 0 to 3 ---')
print(data[0:4])
print('\n---Select last row ---')
print(data[-1:])
---Select all rows from 1 to N ---
Fullname Age Designation SaleAmount Income
1 John 25 Developer 22.55 10000
2 Suresh 32 Analyst 119.47 14000
3 Tracy 30 Admin 200.19 11000
4 Steve 29 HR 44.55 14000
---Select rows from 1 to 2 ---
Fullname Age Designation SaleAmount Income
1 John 25 Developer 22.55 10000
2 Suresh 32 Analyst 119.47 14000
---Select rows from 0 to 3 ---
Fullname Age Designation SaleAmount Income
0 Kane 35 Manager 422.19 12000
1 John 25 Developer 22.55 10000
2 Suresh 32 Analyst 119.47 14000
3 Tracy 30 Admin 200.19 11000
---Select last row ---
Fullname Age Designation SaleAmount Income
4 Steve 29 HR 44.55 14000DataFrame loc 方法示例
loc 方法是理解的重要事项之一。您可以使用 loc[] 一次选择多个列和多行。或者,使用此 Pandas loc[] 通过向其传递整数位置来选择一部分。最后,将此 loc 方法与方括号一起使用以从大型数据集中选择行。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table, index = ['a', 'b', 'c', 'd'])
#print(data)
print('\n---Select b row ---')
print(data.loc['b'])
print('\n---Select c row ---')
print(data.loc['c'])
print('\n---Select b and d rows ---')
print(data.loc[['b', 'd']])
---Select b row ---
name Mike
Age 32
Profession Analyst
Salary 1200000
Name: b, dtype: object
---Select c row ---
name Suresh
Age 30
Profession Admin
Salary 900000
Name: c, dtype: object
---Select b and d rows ---
name Age Profession Salary
b Mike 32 Analyst 1200000
d Tracy 26 HR 1100000第一条语句 data.loc[:, ['name', 'Sale']] 返回 name 和 Sale 列的所有行。在最后一条语句中,data.loc[1:3, ['name', 'Profession', 'Salary']] 返回索引值 1 到 3 的 name、Profession 和 Salary 列的行。
table = {'name': ['Kane', 'John', 'Suresh', 'Tracy', 'Steve'],
'Age': [35, 25, 32, 30, 29],
'Profession': ['Manager', 'Developer', 'Analyst', 'Admin', 'HR'],
'Sale':[422.19, 22.55, 119.470, 200.190, 44.55],
'Salary':[12000, 10000, 14000, 11000, 14000]
}
data = pd.DataFrame(table)
#print(data)
print('\n---Select name, Sale column ---')
print(data.loc[:, ['name', 'Sale']])
print('\n---Select name, Profession, Salary ---')
print(data.loc[:, ['name', 'Profession', 'Salary']])
print('\n---Select rows from 1 to 2 ---')
print(data.loc[1:3, ['name', 'Profession', 'Salary']])
---Select name, Sale column ---
name Sale
0 Kane 422.19
1 John 22.55
2 Suresh 119.47
3 Tracy 200.19
4 Steve 44.55
---Select name, Profession, Salary ---
name Profession Salary
0 Kane Manager 12000
1 John Developer 10000
2 Suresh Analyst 14000
3 Tracy Admin 11000
4 Steve HR 14000
---Select rows from 1 to 2 ---
name Profession Salary
1 John Developer 10000
2 Suresh Analyst 14000
3 Tracy Admin 11000iloc 示例
与 loc[] 类似,DataFrame 也有 iloc[]。但是,这只接受整数值或索引来返回数据。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table, index = ['a', 'b', 'c', 'd'])
#print(data)
print('\n---Select 1st row ---')
print(data.iloc[1])
print('\n---Select 3rd row ---')
print(data.iloc[3])
print('\n---Select 1 and 3 rows ---')
print(data.iloc[[1, 3]])
---Select 1st row ---
name Mike
Age 32
Profession Analyst
Salary 1200000
Name: b, dtype: object
---Select 3rd row ---
name Tracy
Age 26
Profession HR
Salary 1100000
Name: d, dtype: object
---Select 1 and 3 rows ---
name Age Profession Salary
b Mike 32 Analyst 1200000
d Tracy 26 HR 1100000您可以使用 loc、iloc、at 和 iat 来提取或访问单个值。以下示例将向您展示相同的内容。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
import pandas as pd
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table)
#print(data)
print('\nitem at 0, 0 = ', data.iloc[0][0])
print('item at 0, 1 = ', data.loc[0][1])
print('item at 1, Profession = ', data.loc[1]['Profession'])
print('item at 2, 3 = ', data.iat[2, 3])
print('item at 0, Salary = ', data.at[0, 'Salary'])
item at 0, 0 = John
item at 0, 1 = 25
item at 1, Profession = Analyst
item at 2, 3 = 900000
item at 0, Salary = 1000000向 Python Pandas DataFrame 添加新列
在此示例中,我们将向您展示如何向现有 DataFrame 添加新列。data['Sale'] = [422.19, 200.190, 44.55] 添加了一个名为 Sale 的全新列。data['Income'] = data['Salary'] + data['basic'] 通过添加 Salary 列和 basic 列中的值来添加新列 Income。
table = {'name': ['Kane', 'Suresh', 'Tracy'],
'Age': [35, 25, 29],
'Profession': ['Manager', 'Developer', 'HR'],
'Salary': [10000, 14000, 11000],
'basic': [4000, 6000, 4500]
}
data = pd.DataFrame(table)
# Add New Column
data['Sale'] = [422.19, 200.190, 44.55]
print('\n---After adding New Column ---')
print(data)
# Add New Column using existing
data['Income'] = data['Salary'] + data['basic']
print('\n---Total Salary ---')
print(data)
# Add New Calculated Column
data['New_Salary'] = data['Salary'] + data['Salary'] * 0.25
print('\n---After adding New Column ---')
print(data)
---After adding New Column ---
name Age Profession Salary basic Sale
0 Kane 35 Manager 10000 4000 422.19
1 Suresh 25 Developer 14000 6000 200.19
2 Tracy 29 HR 11000 4500 44.55
---Total Salary ---
name Age Profession Salary basic Sale Income
0 Kane 35 Manager 10000 4000 422.19 14000
1 Suresh 25 Developer 14000 6000 200.19 20000
2 Tracy 29 HR 11000 4500 44.55 15500
---After adding New Column ---
name Age Profession Salary basic Sale Income New_Salary
0 Kane 35 Manager 10000 4000 422.19 14000 12500.0
1 Suresh 25 Developer 14000 6000 200.19 20000 17500.0
2 Tracy 29 HR 11000 4500 44.55 15500 13750.0从 DataFrame 中删除列
有两种方法可以从 DataFrame 中删除列。您可以使用 del 或 pop 函数。在此示例中,我们将使用这两个函数从 DataFrame 中删除列。
在这里,del(data['basic']) 删除 basic 列(属于 basic 列的完整行)。x = data.pop('Age') 删除或弹出 Age 列,我们也将打印该弹出的列。接下来,我们使用 drop 函数删除 Sale 列。
import pandas as pd
table = {'name': ['Kane', 'Suresh', 'Tracy'],
'Age': [35, 25, 29],
'Profession': ['Manager', 'Developer', 'HR'],
'Salary': [10000, 14000, 11000],
'basic': [4000, 6000, 4500],
'Sale': [422.19, 200.190, 44.55]
}
data = pd.DataFrame(table)
#print(data)
# Delete existing Columns
del(data['basic'])
print('\n---After Deleting basic Column ---')
print(data)
x = data.pop('Age')
print('\n---After Deleting Age Column ---')
print(data)
print('\n---pop Column ---')
print(x)
y = data.drop(columns = 'Sale')
print('\n---After Deleting Sale Column ---')
print(y)
---After Deleting basic Column ---
name Age Profession Salary Sale
0 Kane 35 Manager 10000 422.19
1 Suresh 25 Developer 14000 200.19
2 Tracy 29 HR 11000 44.55
---After Deleting Age Column ---
name Profession Salary Sale
0 Kane Manager 10000 422.19
1 Suresh Developer 14000 200.19
2 Tracy HR 11000 44.55
---pop Column ---
0 35
1 25
2 29
Name: Age, dtype: int64
---After Deleting Sale Column ---
name Profession Salary
0 Kane Manager 10000
1 Suresh Developer 14000
2 Tracy HR 11000如何删除 DataFrame 行?
在此示例中,我们使用 Pandas drop 函数删除行。
table = {'name': ['Kane', 'Suresh', 'Tracy'],
'Profession': ['Manager', 'Developer', 'HR'],
'Salary': [10000, 14000, 11000],
'Sale': [422.19, 200.190, 44.55]
}
data = pd.DataFrame(table, index = ['a', 'b', 'c'])
#print(data)
x = data.drop('b')
print('\n---After Deleting b row---')
print(x)
y = data.drop('a')
print('\n---After Deleting a row---')
print(y)
---After Deleting b row---
name Profession Salary Sale
a Kane Manager 10000 422.19
c Tracy HR 11000 44.55
---After Deleting a row---
name Profession Salary Sale
b Suresh Developer 14000 200.19
c Tracy HR 11000 44.55如何重命名 DataFrame 列?
在此编程语言中,使用 Pandas rename 函数重命名一个或多个列。在这里,我们使用此函数将 Profession 列重命名为 Qualification,将 Salary 重命名为 Income。
table = {'name': ['John', 'Mike', 'Suresh', 'Tracy'],
'Age': [25, 32, 30, 26],
'Profession': ['Developer', 'Analyst', 'Admin', 'HR'],
'Salary':[1000000, 1200000, 900000, 1100000]
}
data = pd.DataFrame(table)
# data = data.rename(columns = {'Profession': 'Qualification'})
data.rename(columns = {'Profession': 'Qualification'}, inplace = True)
print('\n---After Renaming Column ---')
print(data)
data.rename(columns =
{'Profession': 'Qualification',
'Salary': 'Income'},
inplace = True)
print('\n---After Renaming two Column ---')
print(data)
---After Renaming Column ---
name Age Qualification Salary
0 John 25 Developer 1000000
1 Mike 32 Analyst 1200000
2 Suresh 30 Admin 900000
3 Tracy 26 HR 1100000
---After Renaming two Column ---
name Age Qualification Income
0 John 25 Developer 1000000
1 Mike 32 Analyst 1200000
2 Suresh 30 Admin 900000
3 Tracy 26 HR 1100000head 和 tail
如果您是 R 编程用户,您可能熟悉 head 和 tail 函数。head 函数接受整数值作为参数,并返回给定数量的顶部或第一个记录。
例如,head(5) 返回前 5 条记录。同样,Python pandas DataFrame tail 函数返回底部或最后记录。例如,tail(5) 返回最后 5 条记录或底部 5 条记录。
table = {'name': ['Kane', 'John', 'Mike', 'Suresh', 'Tracy', 'Steve'],
'Age': [35, 25, 32, 30, 26, 29],
'Profession': ['Manager', 'Developer', 'Analyst', 'Admin', 'HR', 'HOD'],
'Sale':[422.19, 22.55, 12.66, 119.470, 200.190, 44.55],
'Salary':[12000, 10000, 8000, 14000, 11000, 14000]
}
data = pd.DataFrame(table)
print('\n---First Five records head()---')
print(data.head())
print('\n---First two records head(2)---')
print(data.head(2))
print('\n---Bottom Five records tail()---')
print(data.tail())
print('\n---last two records tail(2)---')
print(data.tail(2))
---First Five records head()---
name Age Profession Sale Salary
0 Kane 35 Manager 422.19 12000
1 John 25 Developer 22.55 10000
2 Mike 32 Analyst 12.66 8000
3 Suresh 30 Admin 119.47 14000
4 Tracy 26 HR 200.19 11000
---First two records head(2)---
name Age Profession Sale Salary
0 Kane 35 Manager 422.19 12000
1 John 25 Developer 22.55 10000
---Bottom Five records tail()---
name Age Profession Sale Salary
1 John 25 Developer 22.55 10000
2 Mike 32 Analyst 12.66 8000
3 Suresh 30 Admin 119.47 14000
4 Tracy 26 HR 200.19 11000
5 Steve 29 HOD 44.55 14000
---last two records tail(2)---
name Age Profession Sale Salary
4 Tracy 26 HR 200.19 11000
5 Steve 29 HOD 44.55 14000转置 DataFrame
DataFrame 具有转置矩阵的内置功能。为此,您必须使用 df.T
print('\n---Transposed ---')
print(data.T)
---Transposed ---
0 1 2 3 4 5
name Kane John Mike Suresh Tracy Steve
Age 35 25 32 30 26 29
Profession Manager Developer Analyst Admin HR HOD
Sale 422.19 22.55 12.66 119.47 200.19 44.55
Salary 12000 10000 8000 14000 11000 14000Python pandas DataFrame groupby
DataFrame groupby 函数类似于 SQL Server 中的 Group By 子句。您可以使用此 Pandas groupby 函数按某些列对数据进行分组,并查找其他列的聚合结果。这是处理实时数据时重要的函数概念之一。
在此示例中,我们创建了一个包含不同列和数据类型的表。然后,我们使用了这个 groupby 函数。第一个语句 data.groupby('Profession').sum() 按 Profession 列对数据框进行分组,并计算 Sales、Salary 和 Age 的总和。
第二个语句 data.groupby(['Profession', 'Age']).sum() 按 Profession 和 Age 列对数据框进行分组,并计算 Sales 和 Salary 的总和。请记住,任何字符串列(无法聚合)都将被连接或组合。
print('\n--- groupby Profession---')
print(data.groupby('Profession').sum())
print('\n--- groupby Profession and Age---')
print(data.groupby(['Profession', 'Age']).sum())
--- groupby Profession---
name Age Sale Salary
Profession
Admin Suresh 30 119.47 14000
Analyst Mike 32 12.66 8000
Developer John 25 22.55 10000
HOD Steve 29 44.55 14000
HR Tracy 26 200.19 11000
Manager Kane 35 422.19 12000
--- groupby Profession and Age---
name Sale Salary
Profession Age
Admin 30 Suresh 119.47 14000
Analyst 32 Mike 12.66 8000
Developer 25 John 22.55 10000
HOD 29 Steve 44.55 14000
HR 26 Tracy 200.19 11000
Manager 35 Kane 422.19 12000Python pandas DataFrame stack
stack 函数会压缩 DataFrame 对象的一个级别。要使用此 stack 函数,您只需调用 data_to_stack.stack()。在此示例中,我们正在对分组数据(groupby 函数结果)使用此 DataFrame stack 函数以进一步压缩它。
grouped_data1 = data.groupby('Profession').sum()
stacked_data1 = grouped_data1.stack()
print('\n---Stacked groupby Profession---')
print(stacked_data1)
grouped_data2 = data.groupby(['Profession', 'Age']).sum()
stacked_data2 = grouped_data2.stack()
print('\n---Stacked groupby Profession and Age---')
print(stacked_data2)
---Stacked groupby Profession---
Profession
Admin name Suresh
Age 30
Sale 119.47
Salary 14000
Analyst name Mike
Age 32
Sale 12.66
Salary 8000
Developer name John
Age 25
Sale 22.55
Salary 10000
HOD name Steve
Age 29
Sale 44.55
Salary 14000
HR name Tracy
Age 26
Sale 200.19
Salary 11000
Manager name Kane
Age 35
Sale 422.19
Salary 12000
dtype: object
---Stacked groupby Profession and Age---
Profession Age
Admin 30 name Suresh
Sale 119.47
Salary 14000
Analyst 32 name Mike
Sale 12.66
Salary 8000
Developer 25 name John
Sale 22.55
Salary 10000
HOD 29 name Steve
Sale 44.55
Salary 14000
HR 26 name Tracy
Sale 200.19
Salary 11000
Manager 35 name Kane
Sale 422.19
Salary 12000
dtype: objectPython pandas DataFrame unstack
unstack 函数会撤消 stack 函数执行的操作,或者说与 stack 函数相反。此 unstack 函数解压缩堆叠 DataFrame(.stack() 函数)的最后一列。要使用此函数,您可以调用 stacked_data.unstack()
grouped_data1 = data.groupby('Profession').sum()
stacked_data1 = grouped_data1.stack()
unstacked_data1 = stacked_data1.unstack()
# print('\n---Stacked groupby Profession---')
# print(stacked_data1)
print('\n---Unstacked groupby Profession---')
print(unstacked_data1)
grouped_data2 = data.groupby(['Profession', 'Age']).sum()
stacked_data2 = grouped_data2.stack()
unstacked_data2 = stacked_data2.unstack()
# print('\n---Stacked groupby Profession and Age---')
# print(stacked_data2)
print('\n---Unstacked groupby Profession and Age---')
print(unstacked_data2)
---Unstacked groupby Profession---
name Age Sale Salary
Profession
Admin Suresh 30 119.47 14000
Analyst Mike 32 12.66 8000
Developer John 25 22.55 10000
HOD Steve 29 44.55 14000
HR Tracy 26 200.19 11000
Manager Kane 35 422.19 12000
---Unstacked groupby Profession and Age---
name Sale Salary
Profession Age
Admin 30 Suresh 119.47 14000
Analyst 32 Mike 12.66 8000
Developer 25 John 22.55 10000
HOD 29 Steve 44.55 14000
HR 26 Tracy 200.19 11000
Manager 35 Kane 422.19 12000DataFrame 连接
concat 函数用于组合或连接对象。首先,我们声明了两个大小为 4 * 6 的随机值 df。然后,我们使用 concat 函数进行连接。
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(4, 6))
print(df1)
df2 = pd.DataFrame(np.random.randn(4, 6))
print(df2)
print('\n--- concatenation---')
print(pd.concat([df1, df2]))
0 1 2 3 4 5
0 0.170510 -0.549890 -0.076595 -1.666645 -0.500168 -0.837365
1 -1.056680 -0.296667 -1.418145 -0.357668 -0.319350 2.131726
2 1.359241 0.913525 -0.590698 -0.460282 1.198779 -0.900188
3 0.550750 -0.186552 0.543404 1.520353 0.288910 0.563674
0 1 2 3 4 5
0 0.748928 -0.095618 -0.490589 0.950306 -0.786737 0.968456
1 -0.561079 0.204682 1.356939 -1.907207 -0.625462 0.163865
2 0.391494 0.881150 0.871912 -0.448490 0.589685 0.271900
3 0.179141 -0.589593 -0.335848 -0.348342 0.516758 0.691327
--- concatenation---
0 1 2 3 4 5
0 0.170510 -0.549890 -0.076595 -1.666645 -0.500168 -0.837365
1 -1.056680 -0.296667 -1.418145 -0.357668 -0.319350 2.131726
2 1.359241 0.913525 -0.590698 -0.460282 1.198779 -0.900188
3 0.550750 -0.186552 0.543404 1.520353 0.288910 0.563674
0 0.748928 -0.095618 -0.490589 0.950306 -0.786737 0.968456
1 -0.561079 0.204682 1.356939 -1.907207 -0.625462 0.163865
2 0.391494 0.881150 0.871912 -0.448490 0.589685 0.271900
3 0.179141 -0.589593 -0.335848 -0.348342 0.516758 0.691327在上面的示例中,我们正在连接两个相同大小的 df 对象。但是,您可以使用此 Python Pandas DataFrame concat 函数连接或组合两个以上不同大小的对象。
为此,我们使用了三个不同大小的随机生成数字的数据框。然后,我们使用该函数连接这三个对象。
dfA = pd.DataFrame(np.random.randn(4, 6))
print(dfA)
dfB = pd.DataFrame(np.random.randn(4, 5))
print(dfB)
dfC = pd.DataFrame(np.random.randn(3, 4))
print(dfC)
print('\n-----concatenation-----')
print(pd.concat([dfA, dfB, dfC]))
0 1 2 3 4 5
0 -0.071220 0.286829 0.726730 -1.046570 1.114306 -0.622870
1 -0.137455 -1.237104 -2.567032 -0.773737 0.446680 1.241036
2 0.417368 -0.544948 -1.368237 -0.409373 -1.757377 1.481192
3 -0.958583 0.116646 0.491579 1.018028 0.591651 1.072710
0 1 2 3 4
0 2.525100 -0.172472 -2.364648 -2.312990 0.264522
1 0.041258 0.688158 1.192806 1.590377 -0.549352
2 0.723508 -1.246208 -0.497221 0.174042 -0.634088
3 -0.394750 1.186304 0.575888 -1.201602 0.851508
0 1 2 3
0 0.038201 -0.987624 -1.347281 0.968429
1 -0.268102 -0.981864 0.378091 0.193392
2 2.287503 0.834575 -0.774165 1.244232
-----concatenation-----
0 1 2 3 4 5
0 -0.071220 0.286829 0.726730 -1.046570 1.114306 -0.622870
1 -0.137455 -1.237104 -2.567032 -0.773737 0.446680 1.241036
2 0.417368 -0.544948 -1.368237 -0.409373 -1.757377 1.481192
3 -0.958583 0.116646 0.491579 1.018028 0.591651 1.072710
0 2.525100 -0.172472 -2.364648 -2.312990 0.264522 NaN
1 0.041258 0.688158 1.192806 1.590377 -0.549352 NaN
2 0.723508 -1.246208 -0.497221 0.174042 -0.634088 NaN
3 -0.394750 1.186304 0.575888 -1.201602 0.851508 NaN
0 0.038201 -0.987624 -1.347281 0.968429 NaN NaN
1 -0.268102 -0.981864 0.378091 0.193392 NaN NaN
2 2.287503 0.834575 -0.774165 1.244232 NaN NaN数学运算
在此示例中,我们使用了一些 DataFrame 数学函数。为了进行此数学运算演示,我们正在查找每个列和每个行的均值和中位数。要获取每行的均值或中位数,您必须在函数中放置整数 1。
table = {'name': ['Kane', 'John', 'Mike', 'Suresh', 'Tracy'],
'Age': [35, 25, 32, 30, 26],
'Profession': ['Manager', 'Developer', 'Analyst', 'Admin', 'HR'],
'Sale':[422.19, 22.55, 12.66, 119.470, 200.190],
'Salary':[12000, 10000, 8000, 14000, 11000]
}
data = pd.DataFrame(table)
#print(data)
print('\n--- Mean of Columns---')
print(data.mean())
print('\n---Mean of Rows---')
print(data.mean(1))
print('\n--- Median of Columns---')
print(data.median())
print('\n--- Median of Rows---')
print(data.median(1))
--- Mean of Columns---
Age 29.600
Sale 155.412
Salary 11000.000
dtype: float64
--- Mean of Rows---
0 4152.396667
1 3349.183333
2 2681.553333
3 4716.490000
4 3742.063333
dtype: float64
--- Median of Columns---
Age 30.00
Sale 119.47
Salary 11000.00
dtype: float64
--- Median of Rows---
0 422.19
1 25.00
2 32.00
3 119.47
4 200.19
dtype: float64我们正在计算每个列的行总和、每行中所有列的总和。同样,使用 sum()、min() 和 max() 函数计算列中的最小值、每个列中的最大值以及每行中的最大值。
table = {'name': ['Kane', 'John', 'Mike', 'Suresh', 'Tracy'],
'Age': [35, 25, 32, 30, 26],
'Profession': ['Manager', 'Developer', 'Analyst', 'Admin', 'HR'],
'Sale':[422.19, 22.55, 12.66, 119.470, 200.190],
'Salary':[12000, 10000, 8000, 14000, 11000]
}
data = pd.DataFrame(table)
#print(data)
print('\n--- sum of Columns---')
print(data.sum())
print('\n--- sum of Rows---')
print(data.sum(1))
print('\n--- Minimum of Columns---')
print(data.min())
print('\n--- Maximum of Columns---')
print(data.max())
print('\n--- Maximum of Rows---')
print(data.max(1))
您可以看到对象的 dtype 和 dtype float64。
--- sum of Columns---
name KaneJohnMikeSureshTracy
Age 148
Profession ManagerDeveloperAnalystAdminHR
Sale 777.06
Salary 55000
dtype: object
--- sum of Rows---
0 12457.19
1 10047.55
2 8044.66
3 14149.47
4 11226.19
dtype: float64
--- Minimum of Columns---
name John
Age 25
Profession Admin
Sale 12.66
Salary 8000
dtype: object
--- Maximum of Columns---
name Tracy
Age 35
Profession Manager
Sale 422.19
Salary 14000
dtype: object
--- Maximum of Rows---
0 12000.0
1 10000.0
2 8000.0
3 14000.0
4 11000.0
dtype: float64DataFrame 上的算术运算
我们将执行算术运算
table = {'Age': [25, 32, 30],
'Sale':[422.19, 119.470, 200.190],
'Salary':[12000, 14000, 11000]
}
data = pd.DataFrame(table)
print(data)
print('\n---Add 20 ---')
print(data + 20)
print('\n---Subtract 10 ---')
print(data - 10)
print('\n---Multiply by 2---')
print(data * 2)
Age Sale Salary
0 25 422.19 12000
1 32 119.47 14000
2 30 200.19 11000
---Add 20 ---
Age Sale Salary
0 45 442.19 12020
1 52 139.47 14020
2 50 220.19 11020
---Subtract 10 ---
Age Sale Salary
0 15 412.19 11990
1 22 109.47 13990
2 20 190.19 10990
---Multiply by 2---
Age Sale Salary
0 50 844.38 24000
1 64 238.94 28000
2 60 400.38 22000Python Pandas DataFrame 空值
isnull 检查并返回 True,如果数据框中的值为 Null;否则,返回 False。notnull 函数返回 True,如果值不为 Null。否则,将返回 False。
import pandas as pd
import numpy as np
table = {'name': ['Kane', 'Suresh', np.nan],
'Profession': ['Manager', np.nan, 'HR'],
'Salary': [np.nan, 14000, 11000],
'Sale': [422.19, np.nan, 44.55]
}
data = pd.DataFrame(table)
print('\n---Checking Nulls ---')
print(data.isnull())
print('\n---Checking Not Nulls ---')
print(data.notnull())
---Checking Nulls ---
name Profession Salary Sale
0 False False True False
1 False True False True
2 True False False False
---Checking Not Nulls ---
name Profession Salary Sale
0 True True False True
1 True False True False
2 False True True True替换 DataFrame 中的空值
我们还可以用重要的数字替换这些 Null 值。因此,要替换空值,请使用 DataFrame fillna 或 replace 函数。
table = {'Age': [20, 35, np.nan],
'Salary': [np.nan, 14000, 11000],
'Sale': [422.19, np.nan, 44.55]
}
data = pd.DataFrame(table)
print('\n---Fill Missing Values ---')
print(data.fillna(30))
print('\n---Replace Missing Values ---')
print(data.replace({np.nan:66}))
---Fill Missing Values ---
Age Salary Sale
0 20.0 30.0 422.19
1 35.0 14000.0 30.00
2 30.0 11000.0 44.55
---Replace Missing Values ---
Age Salary Sale
0 20.0 66.0 422.19
1 35.0 14000.0 66.00
2 66.0 11000.0 44.55将 DataFrame 保存到 CSV 和文本文件
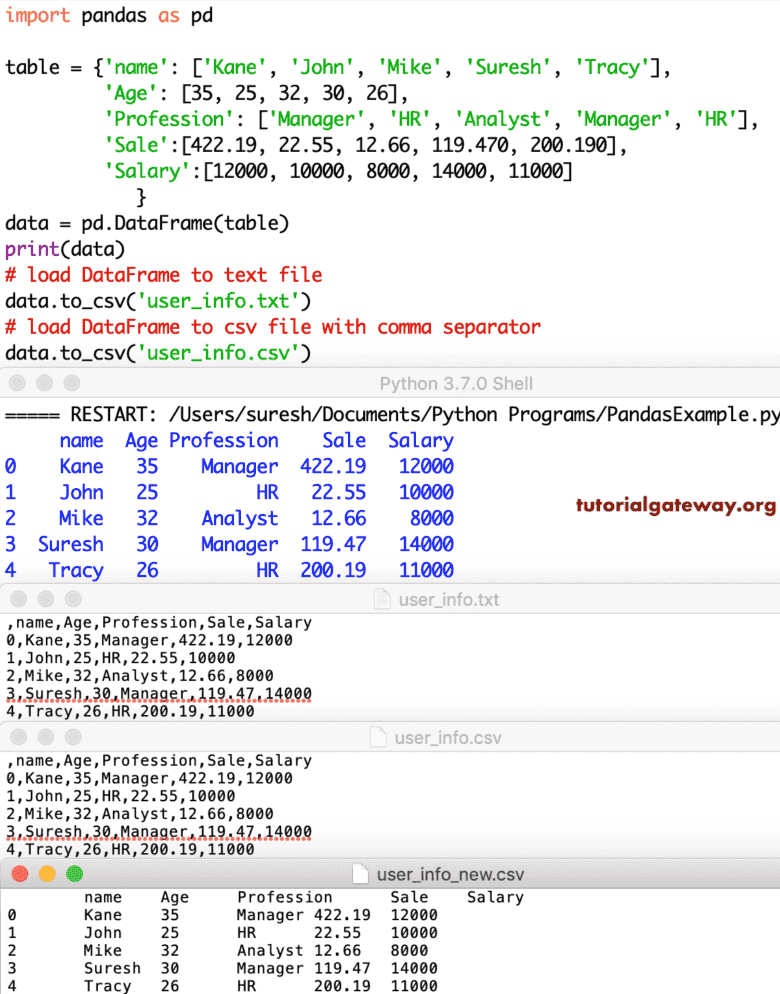
要将数据从 DataFrame 加载到 CSV 文件或文本文件,您必须使用 to_csv 函数。
import pandas as pd
table = {'name': ['Kane', 'John', 'Mike', 'Suresh', 'Tracy'],
'Age': [35, 25, 32, 30, 26],
'Profession': ['Manager', 'HR', 'Analyst', 'Manager', 'HR'],
'Sale':[422.19, 22.55, 12.66, 119.470, 200.190],
'Salary':[12000, 10000, 8000, 14000, 11000]
}
data = pd.DataFrame(table)
print(data)
# load to text file
data.to_csv('user_info.txt')
# load to csv file with comma separator
data.to_csv('user_info.csv')
# load data to csv file with Tab separator
data.to_csv('user_info_new.csv', sep = '\t')
DataFrame pivot
pivot 函数对于透视现有 DataFrame 非常有用。
print('\n--- After Pivot---')
data2 = data.pivot(index = 'name', columns = 'Profession', values = 'Salary')
print(data2)
print('\n--- After Pivot---')
data3 = data.pivot(index = 'name', columns = 'Profession')
print(data3)
--- After Pivot---
Profession Analyst HR Manager
name
John NaN 10000.0 NaN
Kane NaN NaN 12000.0
Mike 8000.0 NaN NaN
Suresh NaN NaN 14000.0
Tracy NaN 11000.0 NaN
--- After Pivot---
Age Sale ... Salary
Profession Analyst HR Manager Analyst ... Manager Analyst HR Manager
name ...
John NaN 25.0 NaN NaN ... NaN NaN 10000.0 NaN
Kane NaN NaN 35.0 NaN ... 422.19 NaN NaN 12000.0
Mike 32.0 NaN NaN 12.66 ... NaN 8000.0 NaN NaN
Suresh NaN NaN 30.0 NaN ... 119.47 NaN NaN 14000.0
Tracy NaN 26.0 NaN NaN ... NaN NaN 11000.0 NaN
[5 rows x 9 columns]迭代 DataFrame 行
使用 iteritems、iterrows 和 itertuple 中的任何一个函数迭代行并返回每行。有关更多信息,请参阅 pandas 模块。
print('\n---Iterating Rows---')
for rows, columns in data.iterrows():
print(rows, columns)
print()
---Iterating Rows---
0 name Kane
Age 35
Profession Manager
Sale 422.19
Salary 12000
Name: 0, dtype: object
1 name John
Age 25
Profession HR
Sale 119.47
Salary 14000
Name: 1, dtype: object
2 name Mike
Age 32
Profession Analyst
Sale 200.19
Salary 11000
Name: 2, dtype: object