Python 中的 pandas DataFrame plot 函数用于绘制图表,正如我们在 matplotlib 中生成的那样。您可以将此 plot 函数用于 Series 和 DataFrame。使用此 DataFrame plot 函数可以绘制的图表列表包括 area、bar、barh、box、density、hexbin、hist、kde、line、pie 和 scatter。
Python pandas DataFrame plot 函数接受的可用参数列表。
- x:默认值为 None。如果数据是 DataFrame,则分配 x 值。
- y(默认值 = None):它允许绘制一列与另一列的对比。
- Kind:它接受指定您想要的图表的字符串值。它们是 area、bar、barh、box、density、hexbin、hist、KDE、line、pie 和 scatter。
- figsize:以英寸为单位的 (宽度, 高度) 元组。
- use_index(默认值 = True):它接受布尔值。使用索引作为 x 轴的刻度。
- title:为图表分配标题。
- grid:轴的网格线,默认值为 None
- legend:它接受 True、False 或 ‘reverse’。
- style:接受列表或字典。每列的线型。
- logx、logy、loglog:使用 logx 对 x 轴进行缩放,使用 logy 对 y 轴进行缩放,使用 loglog 对 x 和 y 轴都进行缩放。
- xticks:xticks 的顺序值。
- yticks:yticks 的序列值。
- xlim、ylim:2-元组或列表。
- rot:xticks 和 yticks 的旋转。xticks 用于垂直图,yticks 用于水平图。
- fontsize:指定整数值以确定 xticks 和 yticks 的字体大小。
- colormap:matplotlib 或 str color map 对象。用于选择颜色。
- colorbar:通过将其设置为 True,用于散点图和 hexbin 图。
- position:指定条形图布局的对齐方式。您可以指定 0 到 1 之间的任何值;默认值为 0.5。这里,0 表示左下角,1 表示右上角。
- table:它接受布尔值,默认值为 False。如果将其设置为 True,它将使用 matplotlib 默认布局绘制一个表。
- yerr:Series、DataFrame、字典、类似数组的值和字符串。
- xerr:Series、DataFrame、字典、类似数组的值和字符串。
- mark_right:默认设置为 True。当我们使用次要 y 轴时,它会自动将列标签标记在右侧。
- **kwds:关键字参数。
Python Pandas DataFrame 绘图函数示例
以下示例列表帮助您使用此 plot 函数创建或生成 area、bar、barh、box、density、hexbin、hist、KDE、line、pie 和 scatter 图表。
让我向您展示我们用于这些示例的Sql Server数据。请参阅Python中的图表数据文章,查看 Employee Sales Table 中的数据。
import pyodbc
import pandas as pd
import matplotlib.pyplot as plt
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome, Sales2019,
Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
print(df)
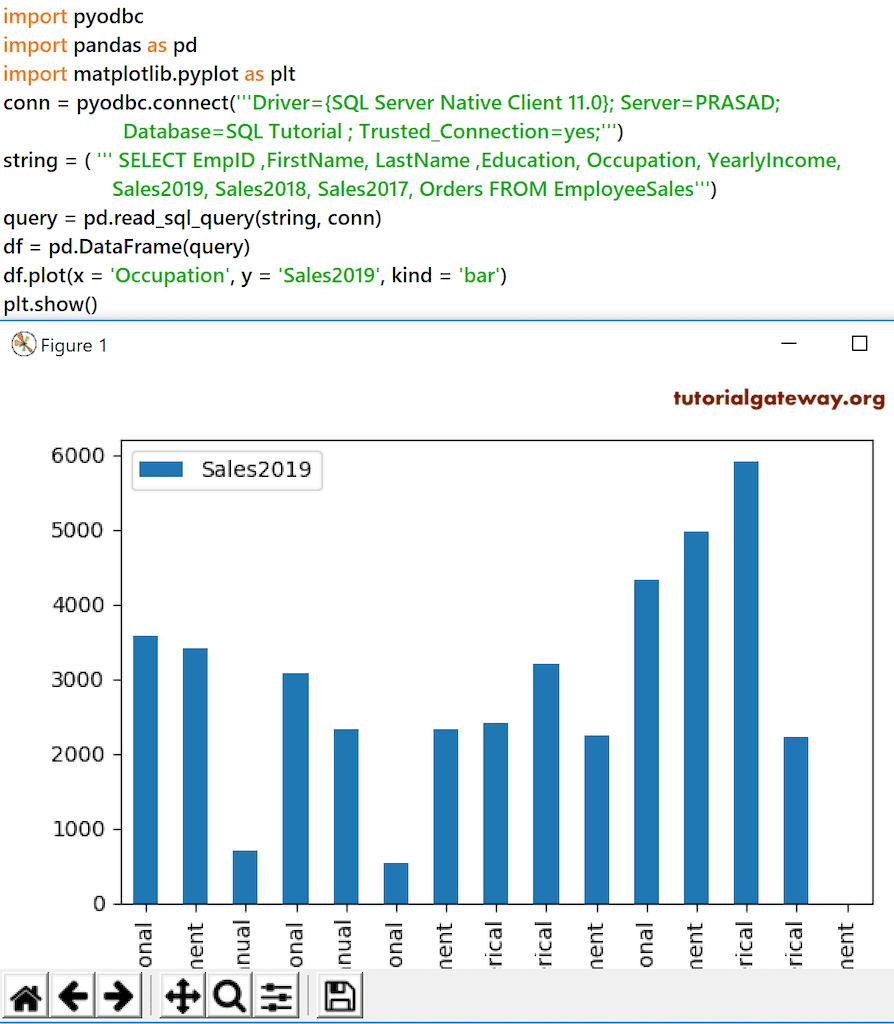
我们将在 Python Pandas plot 函数中使用上面指定的 DataFrame。如您所见,我们将 Occupation 用作 X 轴值,将 Sale2019 用作 Y 轴值,但我们没有指定任何 kind。在这种情况下,dataframe plot 函数会自行决定并根据数据绘制图表。
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome, Sales2019,
Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
df.plot(x = 'Occupation', y = 'Sales2019')
plt.show()
在接下来的示例中,我们仅提及了我们更改过的代码(这为我们节省了一些空间)。但是,您可以在输出图像中看到完整的代码。希望您不介意 :)
Python Pandas DataFrame 条形图
Python 条形图使用矩形条可视化分类数据。您还可以使用它来比较一个条与另一个条。要生成 DataFrame 条形图,我们将 kind 参数值指定为 ‘bar’。为了演示条形图,我们将 Occupation 指定为 X 轴值,将 Sales2019 指定为 Y 轴。
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')ac
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome,
Sales2019, Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
df.plot(x = 'Occupation', y = 'Sales2019', kind = 'bar')
plt.show()
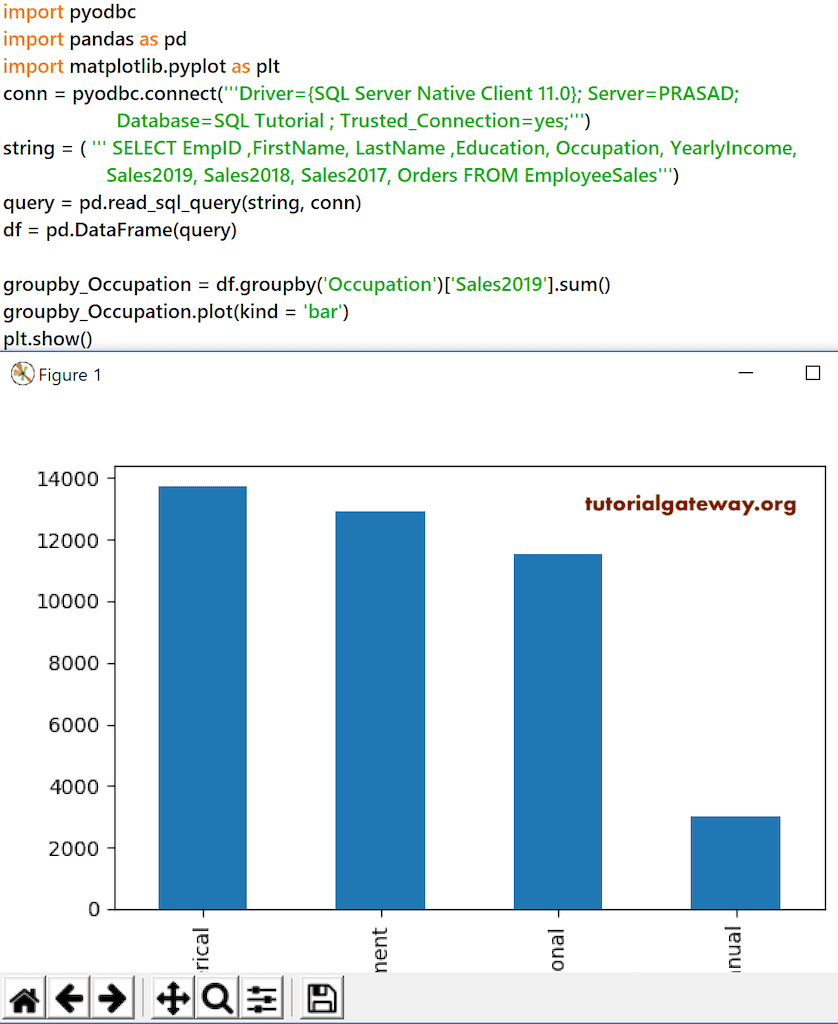
如果我们用 X 轴上的唯一名称(例如 Sales2019 与 Full Name,这是唯一的)生成条形图,那么上面的代码可能对您有用。这里,我们想根据员工职业显示销售额,因此我们需要对这些职业进行分组。为此,我们必须使用 Python pandas DataFrame plot 和 groupby 函数。
groupby_Occupation = df.groupby('Occupation')['Sales2019'].sum()
groupby_Occupation.plot(kind = 'bar')
plt.show()
如果您想使用多个度量或比较今年的销售额与去年,那么您可以尝试以下方法。
groupby_Occupation = df.groupby('Occupation')['Sales2019', 'Sales2018'].sum()
groupby_Occupation.plot(kind = 'bar')
plt.show()
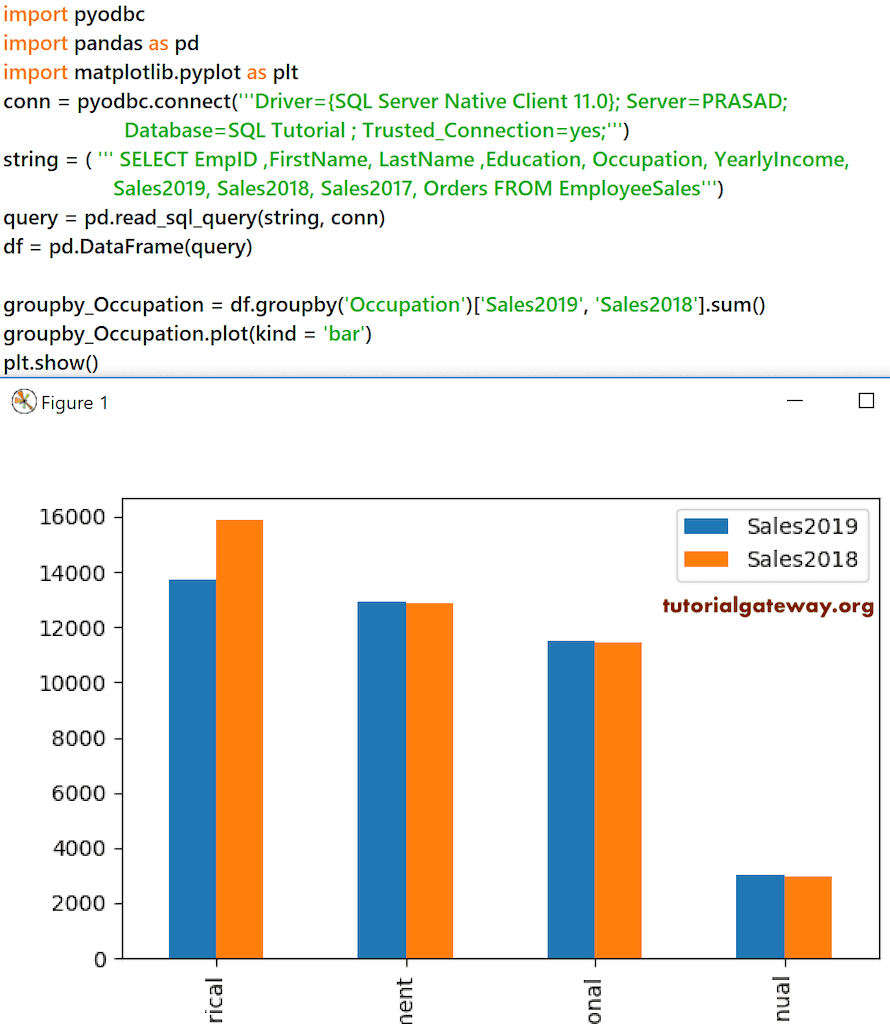
通过使用带有 subplots 参数的 Python pandas DataFrame plot 函数,您可以将条形图分成 2 个子部分。为此,您必须指定 subplots = True。这里,我们使用了 kind = ‘bar’,因为它们都返回相同的结果。
groupby_Occupation = df.groupby('Occupation')['Sales2019', 'Sales2018'].sum()
groupby_Occupation.plot.bar(subplots = True)
plt.show()
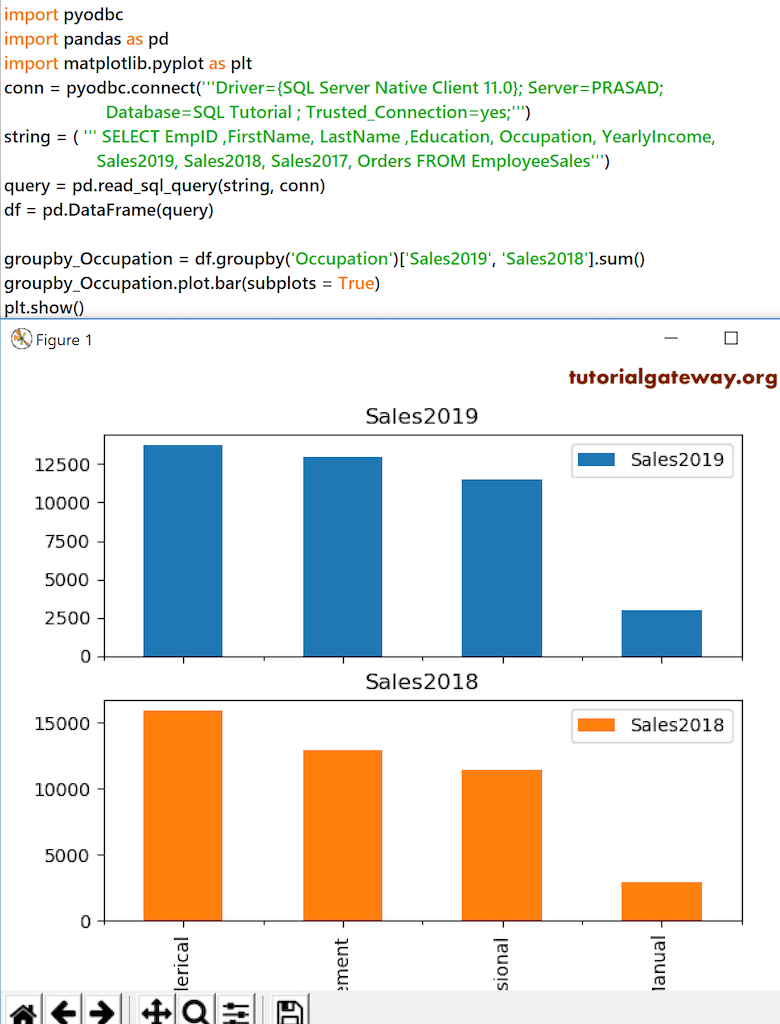
我将使用上面指定的参数进行一些快速格式化。
groupby_Occupation = df.groupby('Occupation')['Sales2019', 'Sales2018'].sum()
groupby_Occupation.plot.bar(title = 'Bar Plot', grid = True, fontsize = 7, position = 1)
plt.show()
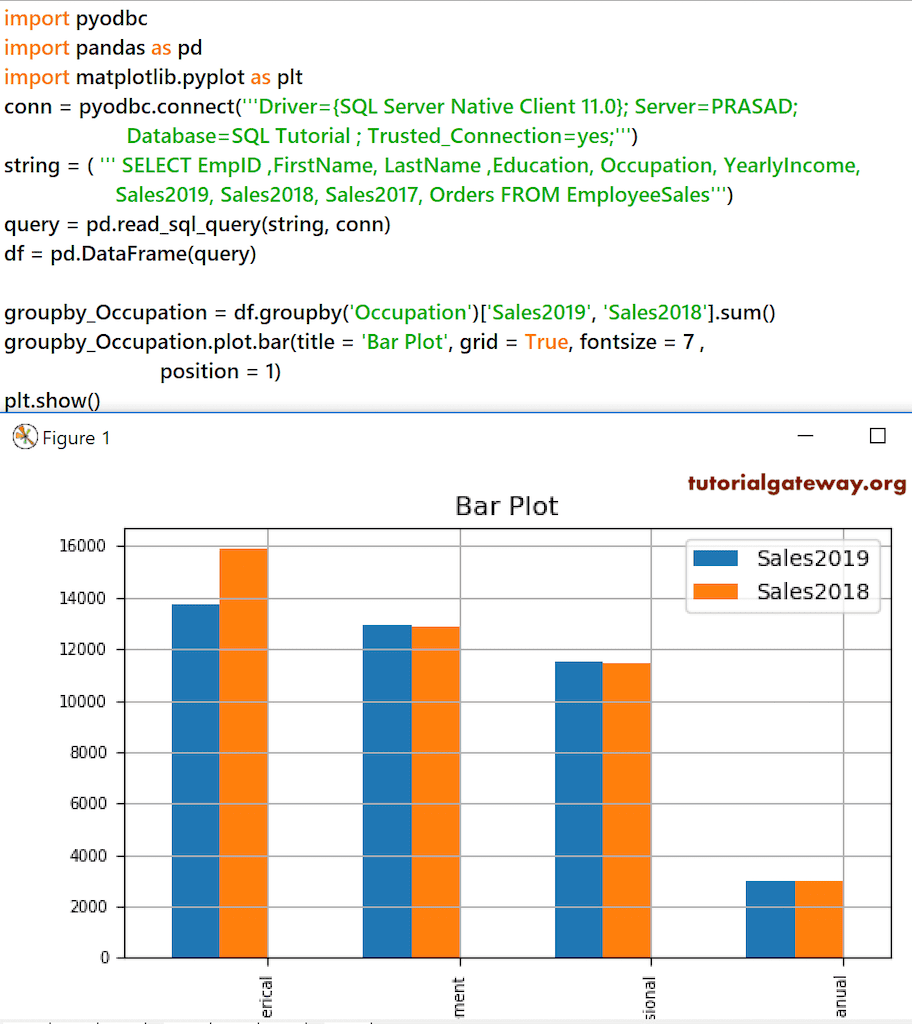
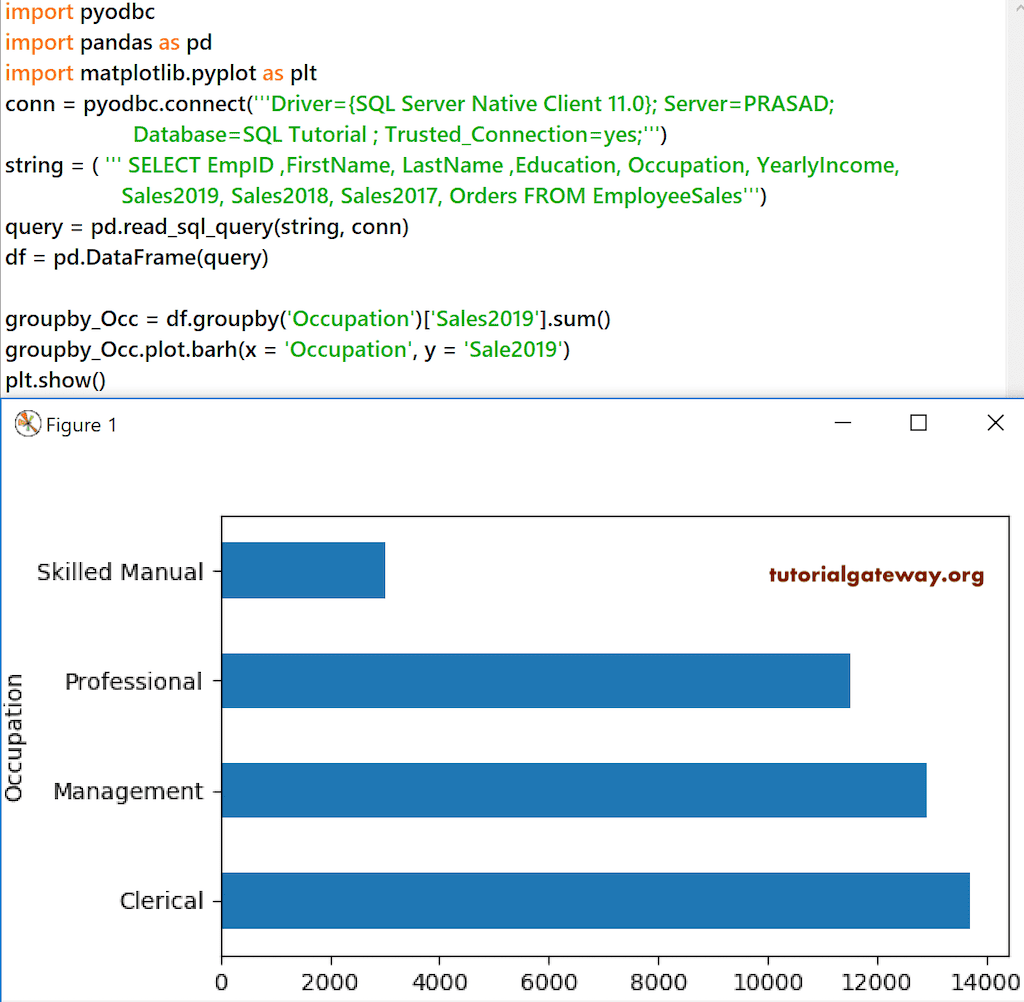
Python Pandas DataFrame 水平绘图
barh 函数允许您绘制水平条形图。您可以使用这些 DataFrame 水平条形图来可视化矩形条中的定量数据。
import pyodbc
import pandas as pd
import matplotlib.pyplot as plt
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome,
Sales2019, Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
groupby_Occ = df.groupby('Occupation')['Sales2019'].sum()
groupby_Occ.plot.barh(x = 'Occupation', y = 'Sale2019' )
plt.show()
我将使用多个数字值作为水平条形图的列。在这里,我们还使用 subplots 分隔了列。
groupby_Occ = df.groupby('Occupation')['Sales2019', 'Sales2018'].sum()
groupby_Occ.plot.barh(title = ['Sales 2019 Bar Plot', 'Sales 2018 Bar Plot'], subplots = True, legend = False)
plt.show()

Python Pandas DataFrame 面积图
面积图用于可视化定量数据。它是一种折线图。但是,它会填充空白区域。
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome,
Sales2019, Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
groupby_Occ = df.groupby('Occupation')['Orders'].sum()
groupby_Occ.plot(x = 'Occupation', y = 'Sale2019', kind = 'area' )
plt.show()
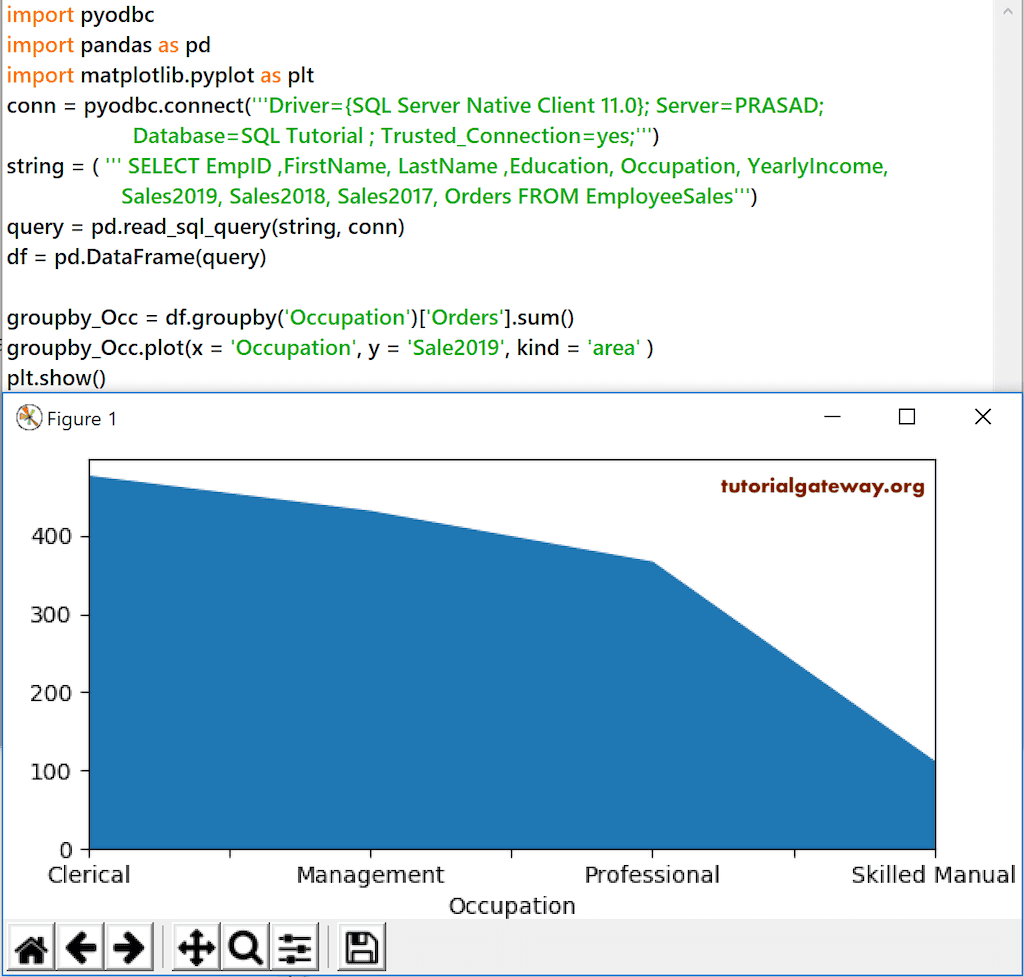
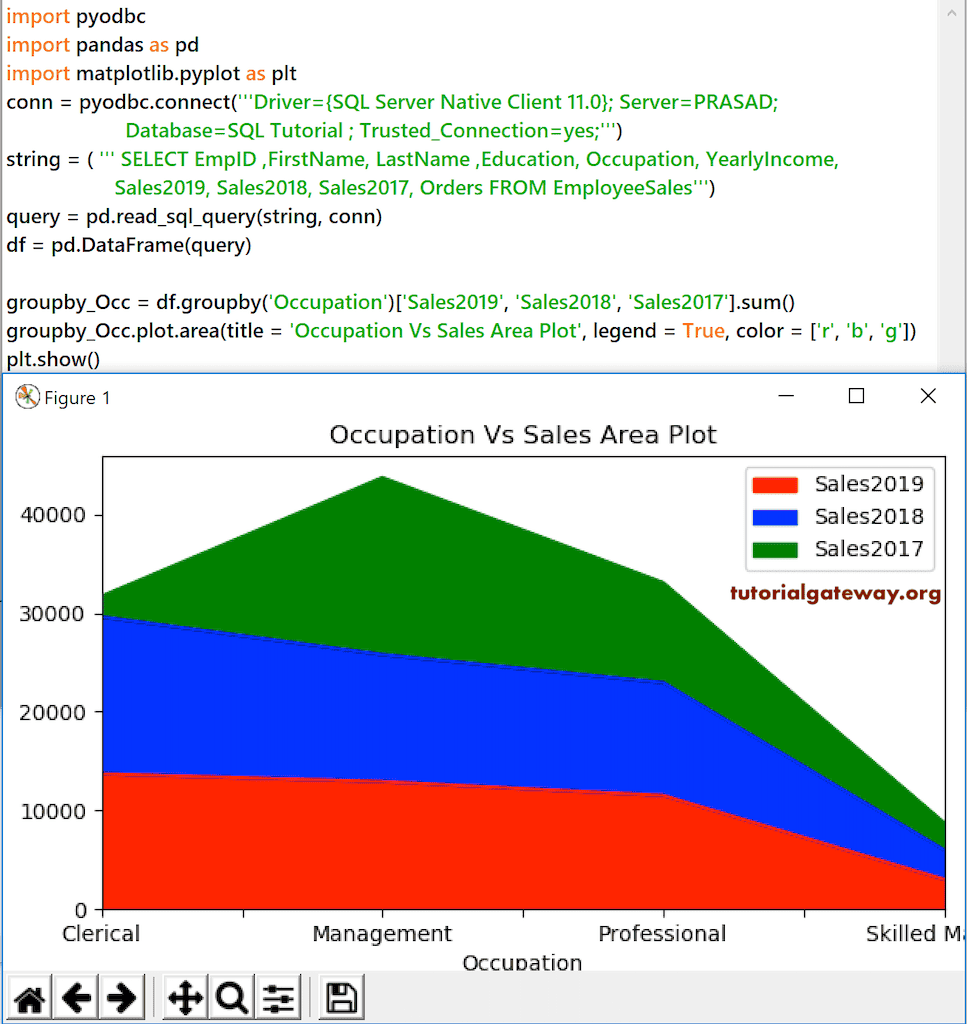
这次,我们将 Occupation 按 Sales 2019、2018 和 2017 分组。接下来,我们使用 plot area 函数绘制面积图。
groupby_Occ = df.groupby('Occupation')['Sales2019', 'Sales2018', 'Sales2017'].sum()
groupby_Occ.plot.area(title = 'Occupation Vs Sales Area Plot', legend = True, color = ['r', 'b', 'g'])
plt.show()
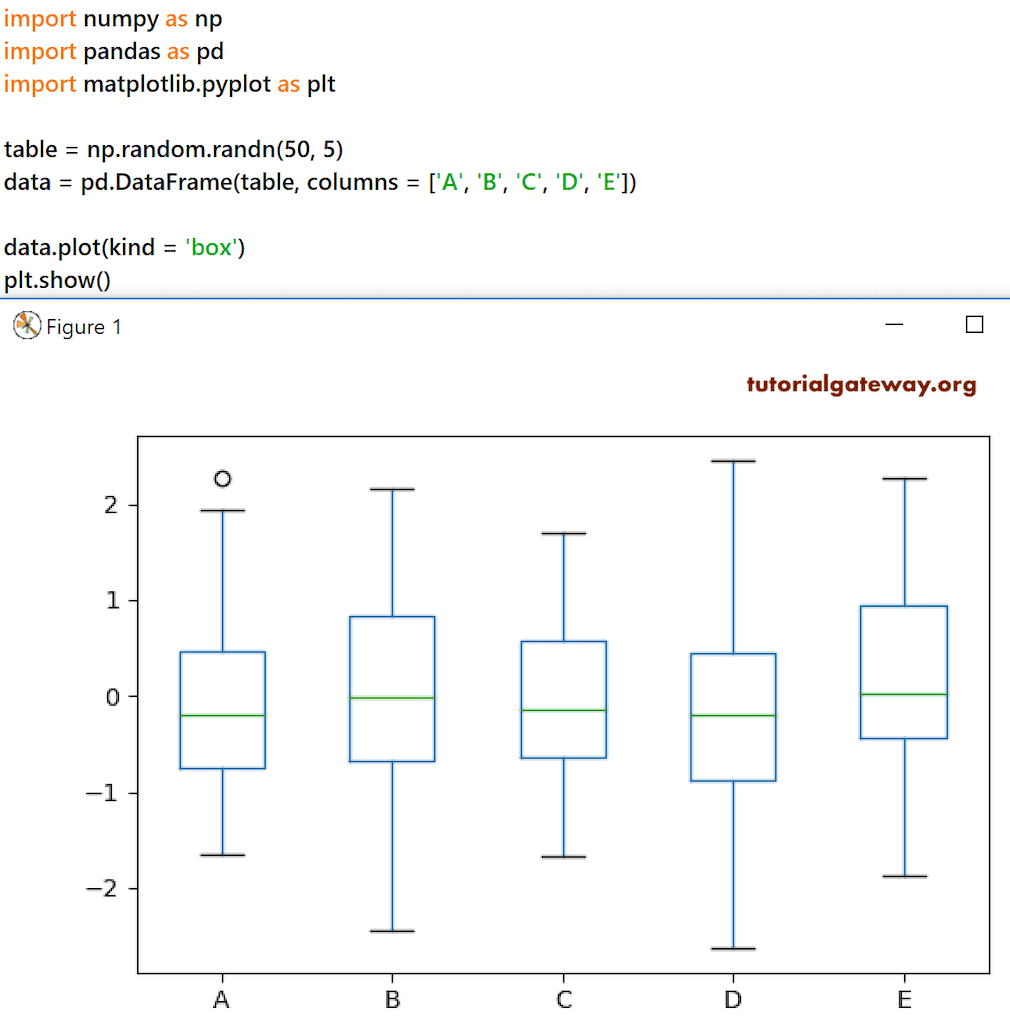
Python pandas DataFrame 箱线图
箱线图用于从给定的 DataFrame 创建箱线图。使用此 DataFrame boxplot 可视化具有四分位数的 数据。在此示例中,我们创建了一个具有 50 行和 5 列的随机 DataFrame,并将列名从 A 到 E 进行了分配。通过使用这些值,我们在 plot 方法的帮助下,并结合 kind = ‘box’ 生成了一个箱线图。
table = np.random.randn(50, 5) data = pd.DataFrame(table, columns = ['A', 'B', 'C', 'D', 'E']) data.plot(kind = 'box') plt.show()
这里,我们使用了 Employees 表中的 FirstName、Sales2019、Sales2018 和 Sales2017 列来绘制箱线图。为此,我们使用了 pandas box 函数。
import pyodbc
import pandas as pd
import matplotlib.pyplot as plt
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT FirstName, Sales2019, Sales2018, Sales2017 FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
df.plot.box(title = 'Box Plot')
plt.show()

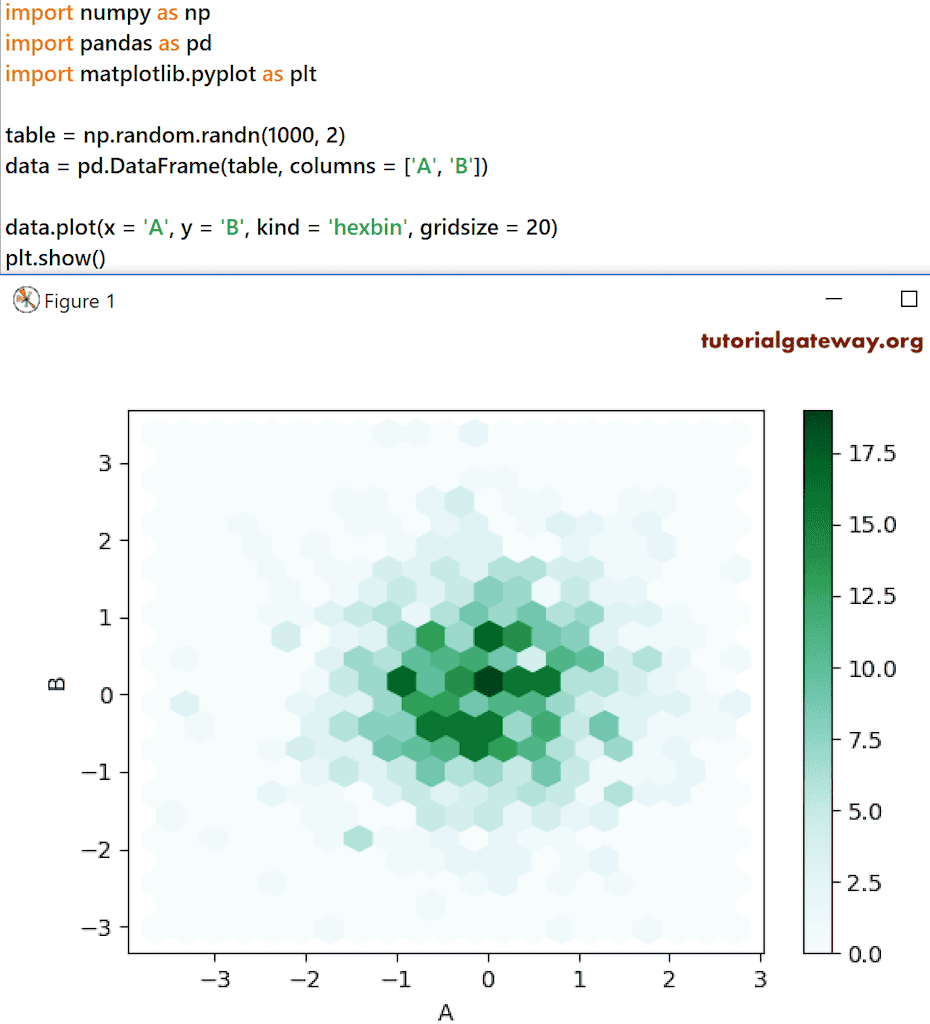
Python Pandas DataFrame hexbin 图
hexbin 图用于生成六边形分箱图。
首先,我们使用 Numpy 的 random randn 函数生成大小为 1000 * 2 的随机数。接下来,我们使用 DataFrame 函数将其转换为具有列名 A 和 B 的 DataFrame。data.plot(x = ‘A’, y = ‘B’, kind = ‘hexbin’, gridsize = 20) 使用这些随机值创建了一个 hexbin 或十六进制分箱图。
import numpy as np import pandas as pd import matplotlib.pyplot as plt table = np.random.randn(1000, 2) data = pd.DataFrame(table, columns = ['A', 'B']) data.plot(x = 'A', y = 'B', kind = 'hexbin', gridsize = 20) plt.show()
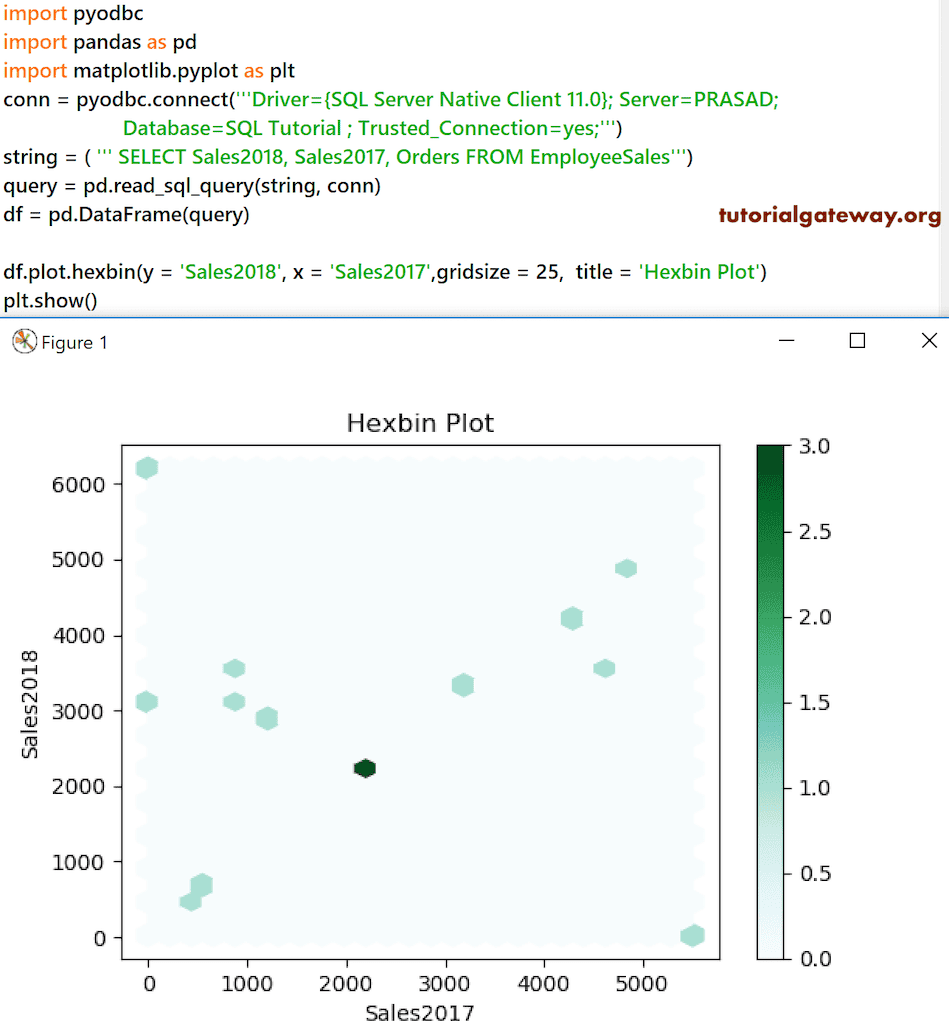
目前,我们当前表中的数据不足以显示十六进制分箱图。因此,我们使用了 Sales 2018 对比 2017,网格大小为 25。
import pyodbc
import pandas as pd
import matplotlib.pyplot as plt
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD; Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
df.plot.hexbin(y = 'Sales2018', x = 'Sales2017',gridsize = 25, title = 'Hexbin Plot')
plt.show()
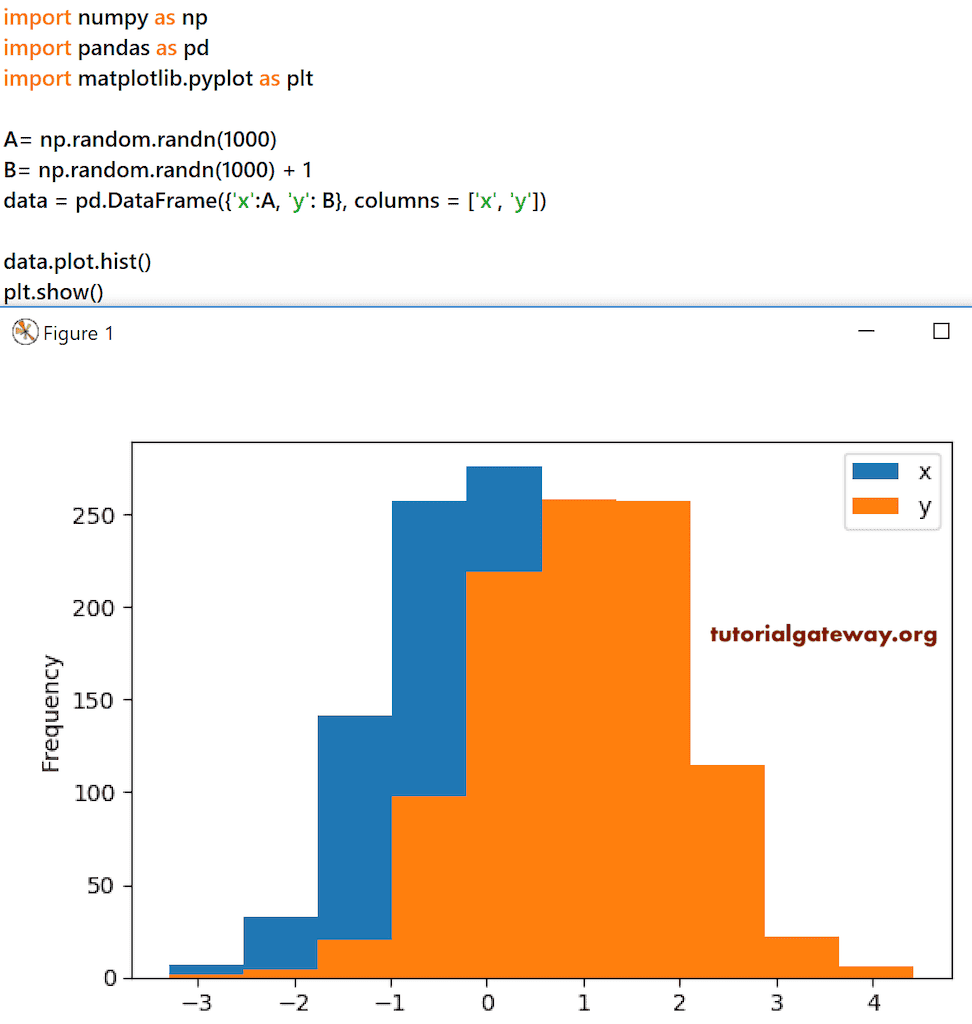
直方图
Python pandas DataFrame hist plot 用于绘制或生成分布数据的直方图。在此示例中,我们使用 random randn 函数为 x 和 y 列生成了随机值。接下来,我们使用了 Pandas hist 函数,而不是生成 Python 中的直方图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
A= np.random.randn(1000)
B= np.random.randn(1000) + 1
data = pd.DataFrame({'x':A, 'y': B}, columns = ['x', 'y'])
data.plot.hist()
plt.show()
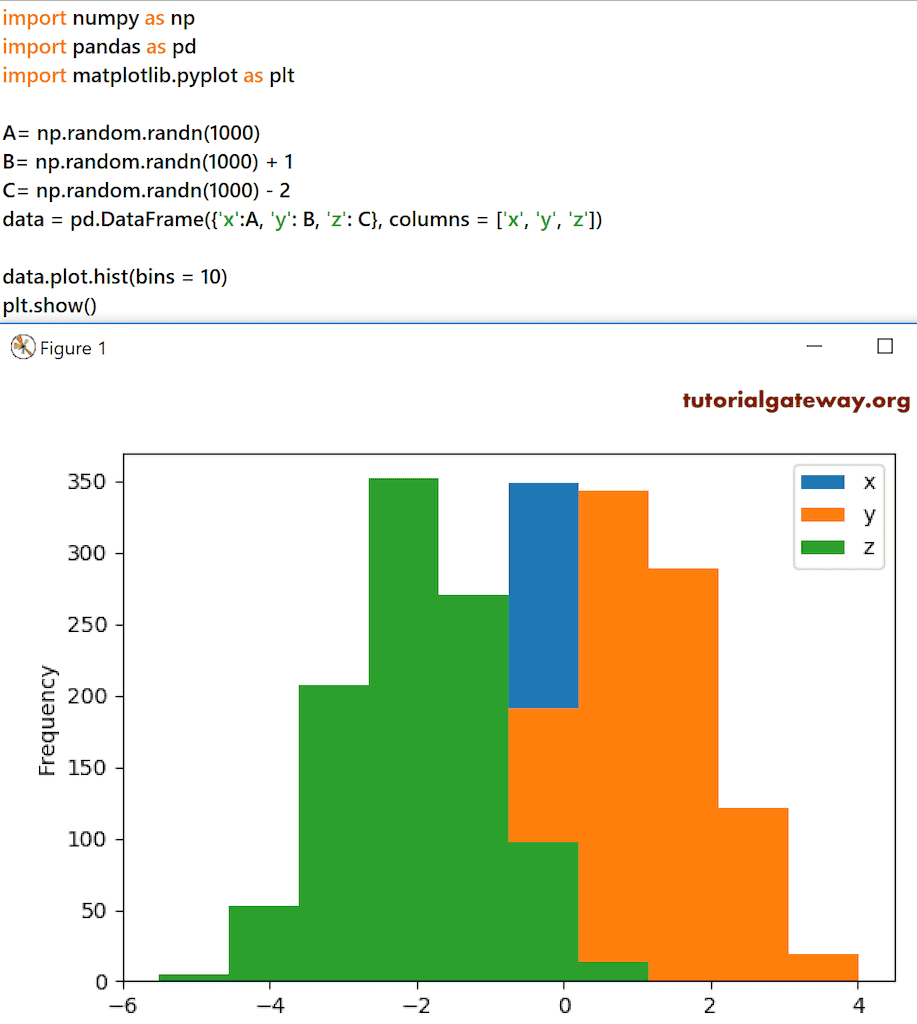
这次我们将 bin 的总数改为了 10,并向 DataFrame 添加了另一列。
A= np.random.randn(1000)
B= np.random.randn(1000) + 1
C= np.random.randn(1000) - 2
data = pd.DataFrame({'x':A, 'y': B, 'z': C}, columns = ['x', 'y', 'z'])
data.plot.hist(bins = 10)
plt.show()
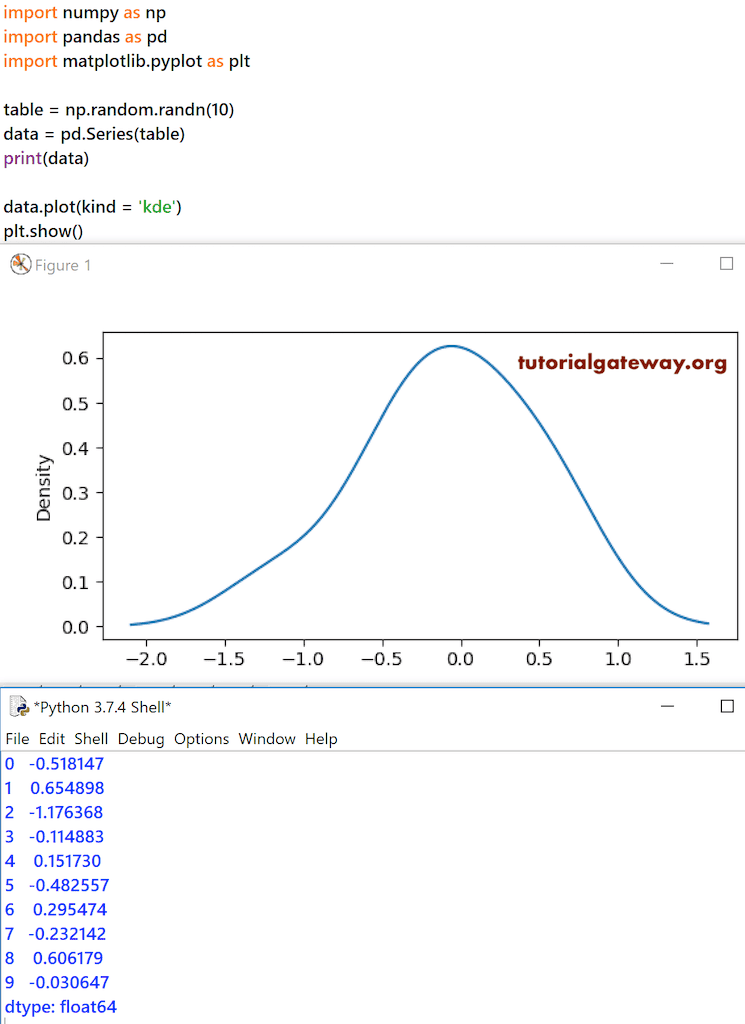
DataFrame kde 图
Python pandas DataFrame kde 使用高斯核生成或绘制核密度估计图(简称 kde)。首先,我们使用 Numpy random 函数生成了 10 个随机数。接下来,我们使用 Pandas Series 函数来创建使用这些数字的 Series。最后,data.plot(kind = ‘kde’) 使用这些数字生成了 kde 或密度图。
table = np.random.randn(10) data = pd.Series(table) print(data) data.plot(kind = 'kde') plt.show()
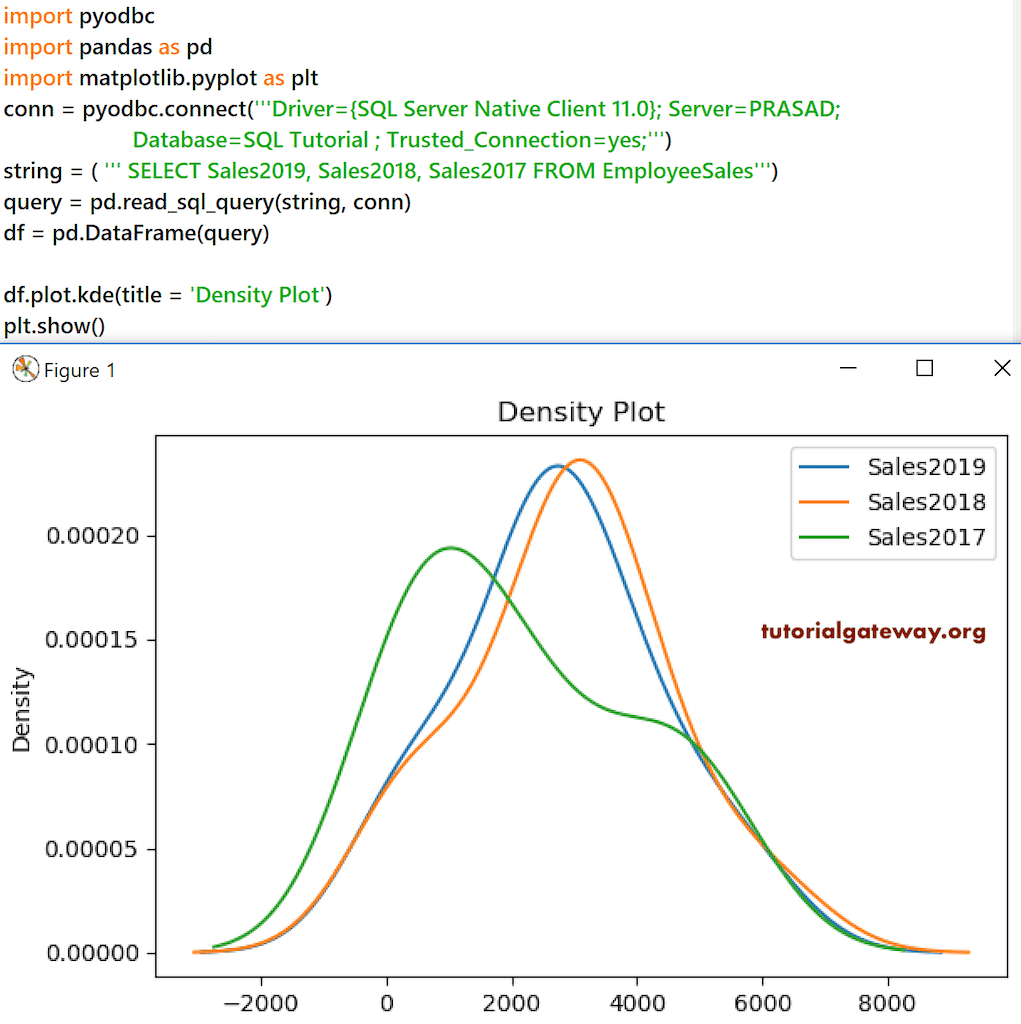
我来为 Employees 表 DataFrame 中最近三年的销售额绘制一个密度图。
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT Sales2019, Sales2018, Sales2017 FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
df.plot.kde(title = 'Density Plot')
plt.show()
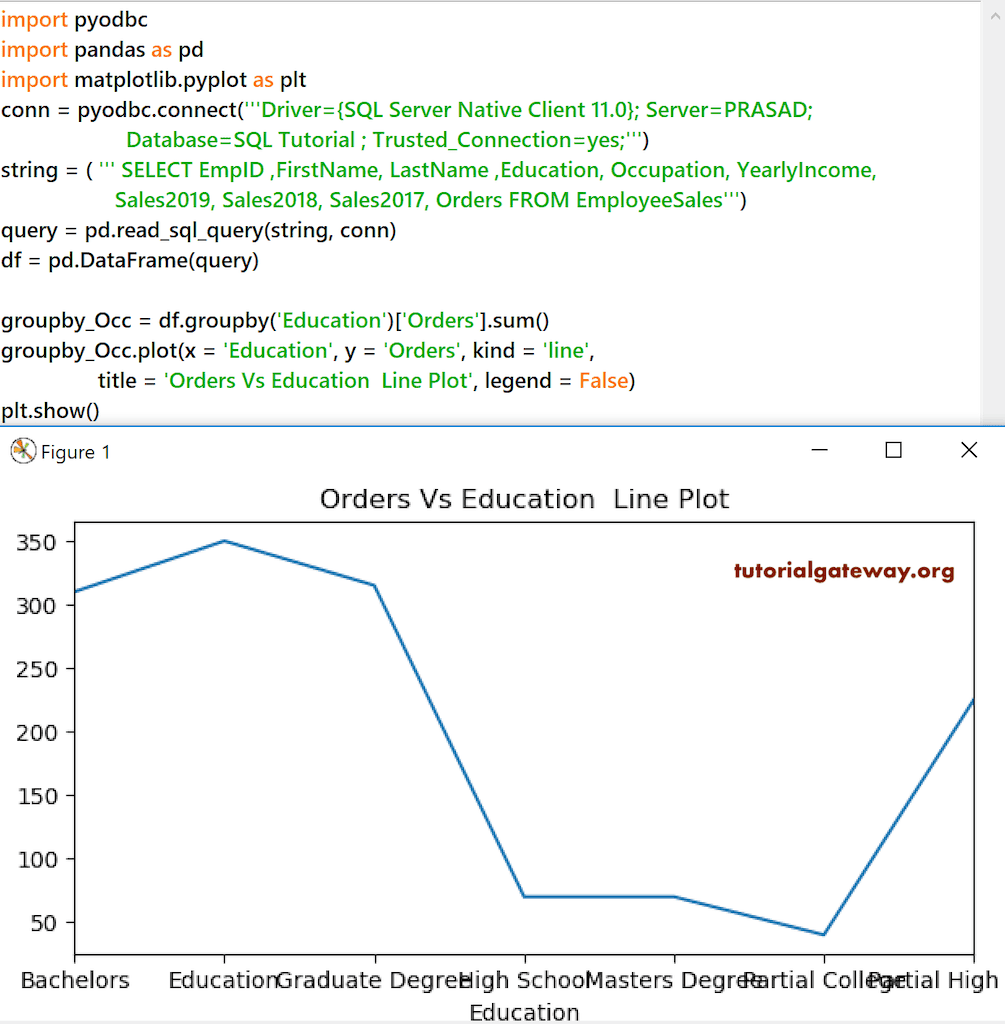
Python Pandas DataFrame 折线图
折线图用于绘制给定数据的线。您可以使用此折线 DataFrame 来绘制一个维度与一个或多个度量的关系。在这里,我们绘制了员工教育程度与订单的 Pandas 折线图。
import pyodbc
import pandas as pd
import matplotlib.pyplot as plt
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome,
Sales2019, Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
groupby_Occ = df.groupby('Education')['Orders'].sum()
groupby_Occ.plot(x = 'Education', y = 'Orders', kind = 'line',
title = 'Orders Vs Education Line', legend = False)
plt.show()
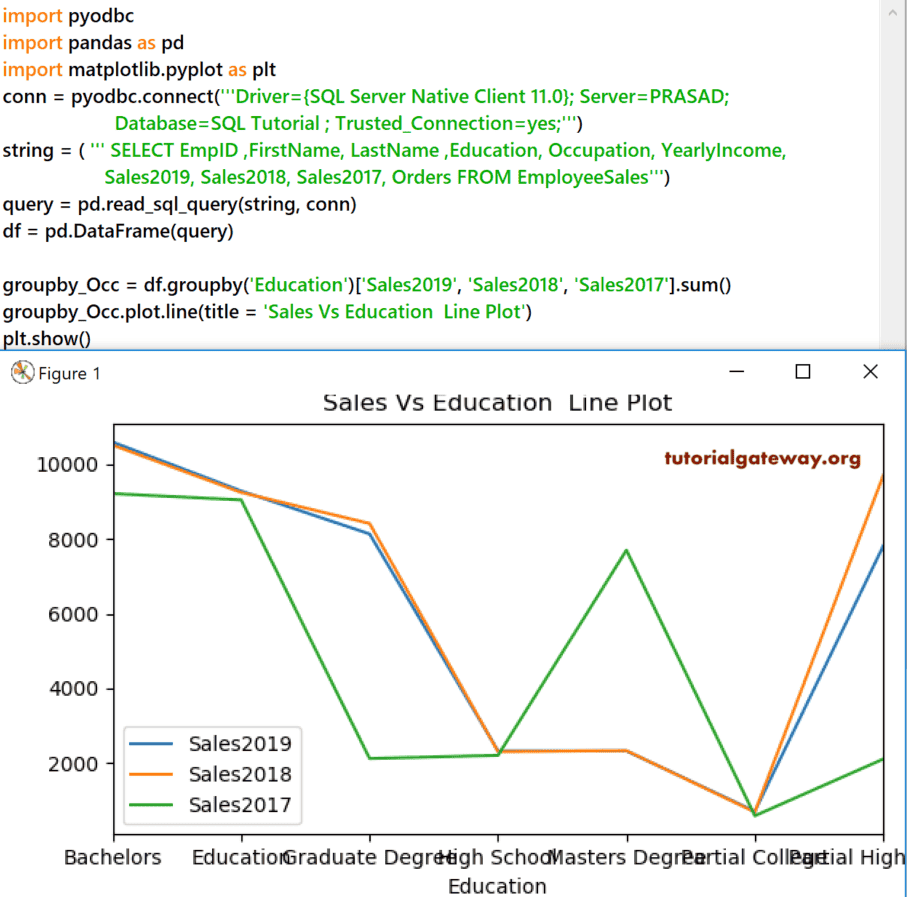
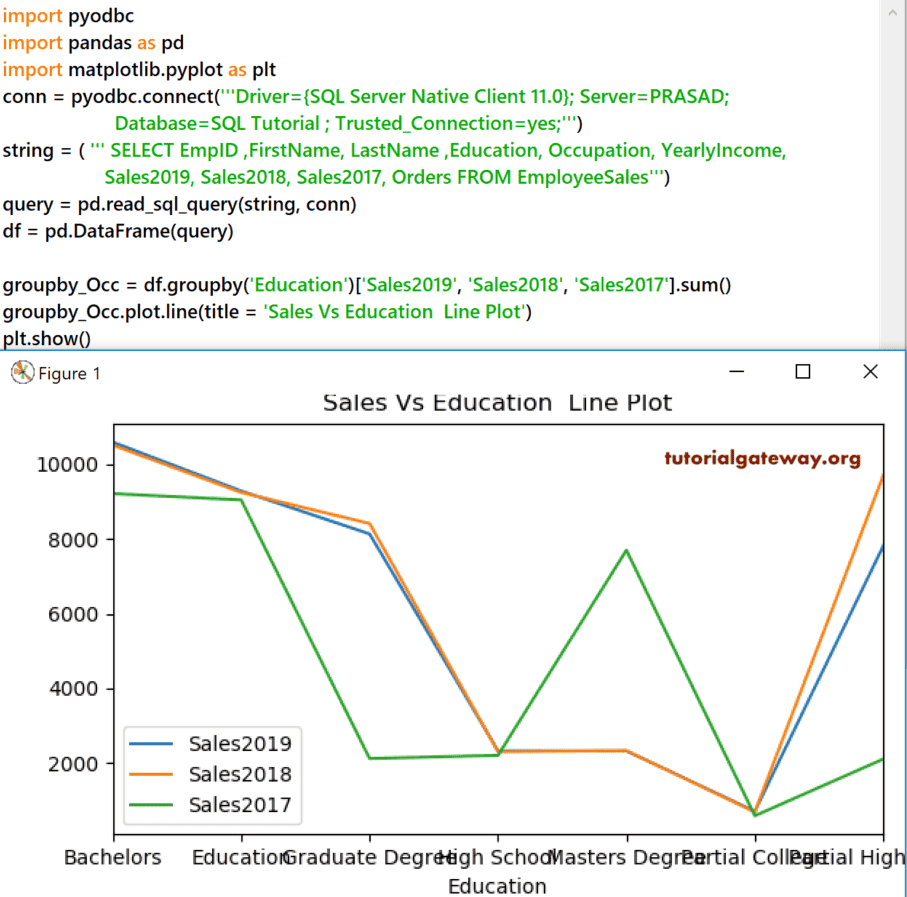
我们将 Education 按 Sales 2019、2018 和 2017 分组。接下来,我们使用 line 函数绘制了折线图。您也可以在 line 函数中使用 subplots = True 来分隔这些销售额折线。
groupby_Occ = df.groupby('Education')['Sales2019', 'Sales2018', 'Sales2017'].sum()
groupby_Occ.plot.line(title = 'Sales Vs Education Line')
plt.show()
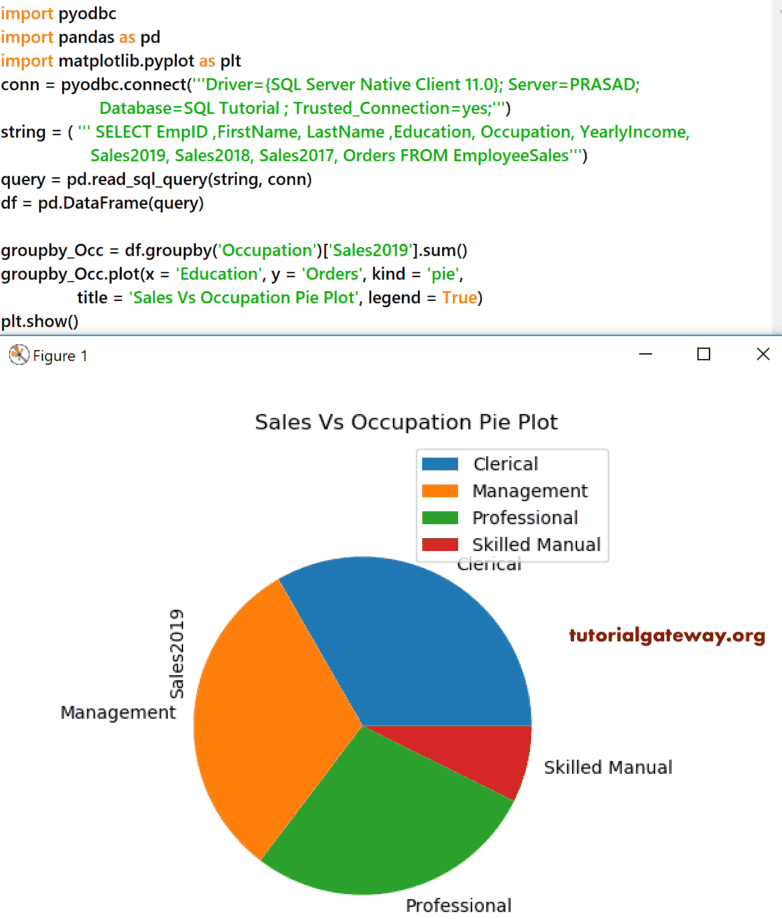
DataFrame 饼图
Python pandas DataFrame plot Pie 用于绘制饼图。它根据传递给它的数字数据列来分割饼图。在这里,我们使用 plot 方法生成了饼图,其中 x = Occupation,y = Sales2019。
import pyodbc
import pandas as pd
import matplotlib.pyplot as plt
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome,
Sales2019, Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
groupby_Occ = df.groupby('Occupation')['Sales2019'].sum()
groupby_Occ.plot(x = 'Education', y = 'Orders', kind = 'pie',
title = 'Sales Vs Occupation Pie Chart', legend = True)
plt.show()
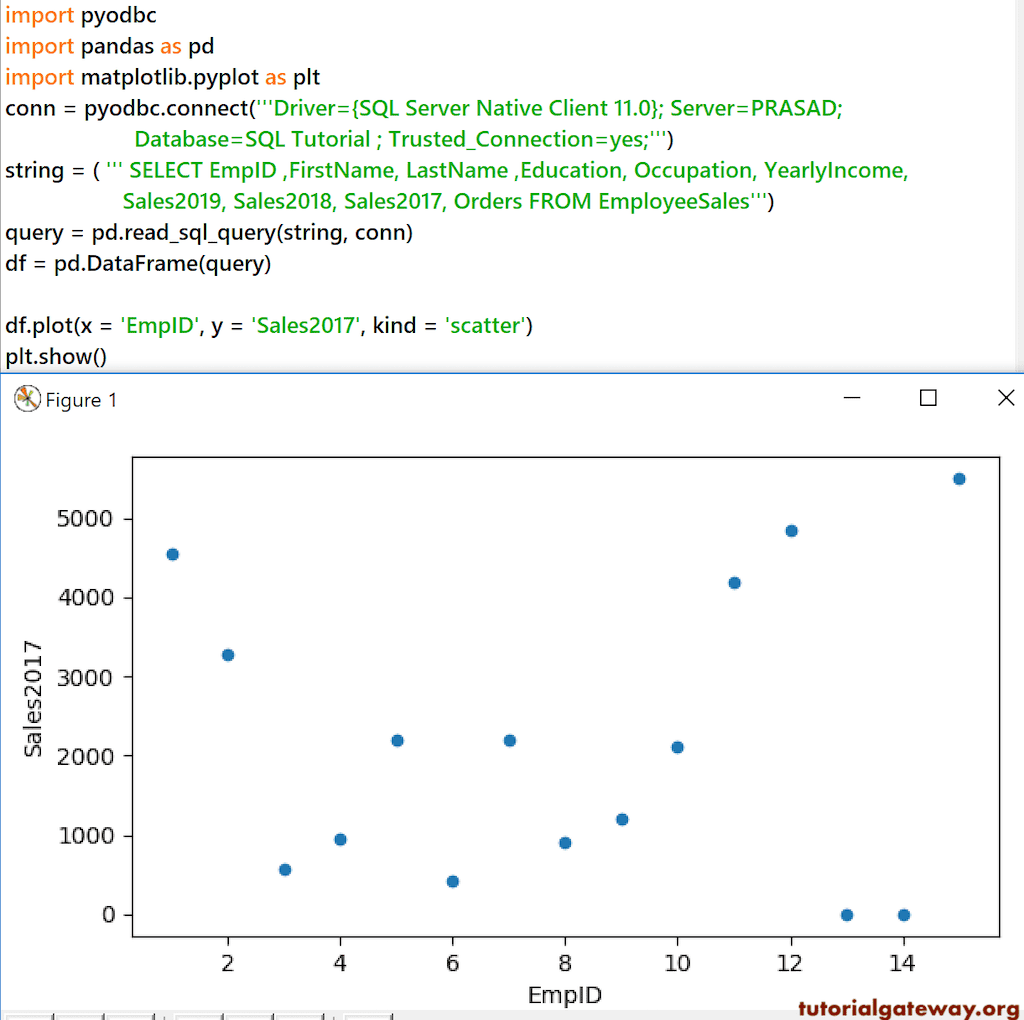
Python Pandas DataFrame 散点图
DataFrame 散点图根据给定的数据创建或标记点。每个标记定义了 DataFrame 中 X 和 Y 轴值的坐标。
conn = pyodbc.connect('''Driver={SQL Server Native Client 11.0}; Server=PRASAD;
Database=SQL Tutorial ; Trusted_Connection=yes;''')
string = ( ''' SELECT EmpID ,FirstName, LastName ,Education, Occupation, YearlyIncome,
Sales2019, Sales2018, Sales2017, Orders FROM EmployeeSales''')
query = pd.read_sql_query(string, conn)
df = pd.DataFrame(query)
df.plot(x = 'EmpID', y = 'Sales2017', kind = 'scatter')
plt.show()
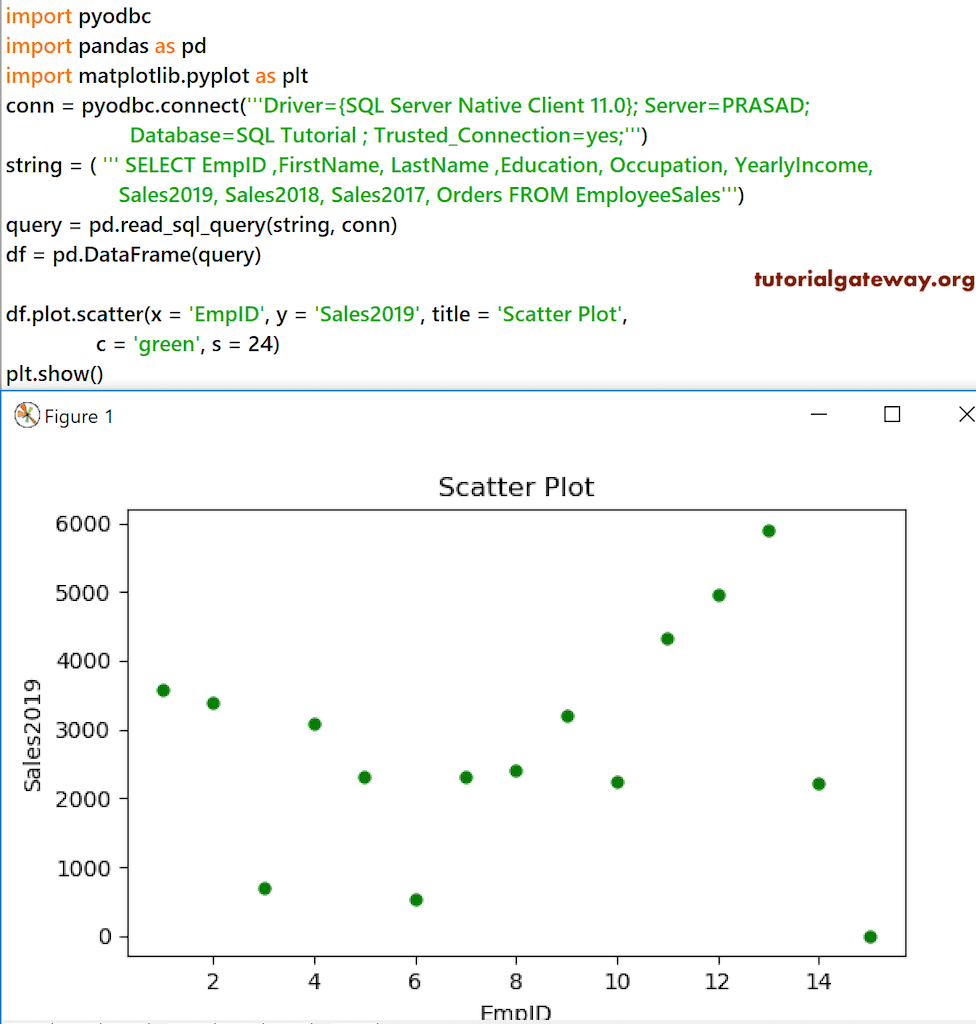
在这里,我们将 X 轴值用作 EmpID,y 轴值用作 Sales 2019。接下来,我们将点的颜色改为了绿色,并将大小也进行了调整。
df.plot.scatter(x = 'EmpID', y = 'Sales2019', title = 'Scatter Plot',c = 'green', s = 24) plt.show()