Java codePointCount 方法是 String 方法中的一种,用于计算指定文本范围内的 Unicode 代码点数量。在本文中,我们将通过示例展示如何在该编程语言中使用 codePointCount。codePointCount 的基本语法如下所示。
public int codePointCount(int Starting_Index, int End_Index) //In order to use in program String_Object.codePointCount(int Starting_Index, int End_Index)
- String_Object:请指定有效的 String 对象。
- 起始索引 (Starting_Index):请指定第一个字符的索引位置。
- 结束索引 (End_Index):请指定最后一个字符之前的索引位置。
Java codePointCount 函数将计算从 Starting_Index 到 End_Index – 1 的 Unicode 代码点数量。从数学上讲,返回值表示为 (End_Index – Starting_Index)。
例如,codePointCount(12, 20) 的输出将是 8,因为 20 – 12 = 8。如果我们提供超出范围的索引位置或负值,codePointCount 函数将抛出错误。
Java codePointCount 示例
在此程序中,我们将使用 string codePointCount 方法来计算指定范围内的 Unicode 代码点数量。
package StringFunctions;
public class CodePointCount {
public static void main(String[] args) {
String str = "Learn Free Java Tutorial";
int a = str.codePointCount(0, 3);
int b = str.codePointCount(4, 11);
int c = str.codePointCount(12, str.length()- 1);
int d = str.codePointCount(0, str.length()- 1);
System.out.println( "Total Unicode Points from 0 to Index position 3 = " + a);
System.out.println( "Total Unicode Points from 4 to Index position 11 = " + b);
System.out.println( "Total Unicode Points from 12 to Last Index position = " + c);
System.out.println( "Total Unicode Points from 0 to Last Index position = " + d);
}
}
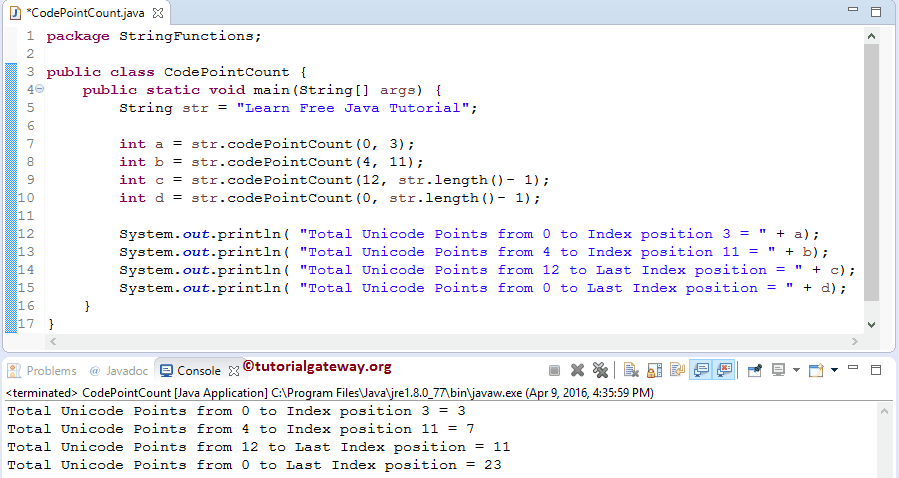
在以下 codePointCount 语句中,第一个语句将查找 0 到 3 之间的 Unicode 代码点数量,另一个将查找 4 到 11 之间的 Unicode 代码点数量。
int a = str.codePointCount(0, 3); int b = str.codePointCount(4, 11);
如果您观察上面的截图,str.codePointCount(0, 3) 返回 3。这是因为 0 和 3 之间有三个 Unicode 代码点,即 (3 – 0 = 3)。您应该将空格计算为一个字符。
在接下来的两行中,我们将 Java codePointCount 方法与 length 函数一起使用来计算字符串长度。
int c = str.codePointCount(12, str.length()- 1); int d = str.codePointCount(0, str.length()- 1);
从上面的 String 方法代码片段中,我们从字符串长度中减去 1。因为字符串的长度是从 1 到 n 计算的,而索引位置从 0 开始,到 n – 1 结束。以下四个 Java System.out.println 语句将打印输出。
评论已关闭。