如何编写 SQL Server 中删除或移除重复行的查询,这是你可能会遇到的常见面试问题之一。
对于这个删除重复行或记录的例子,我们将使用下面显示的数据(Adventure Works DW 中用于移除的 Fact Internet Sales 的几列)。
USE [AdventureWorksDW2014]
GO
SELECT [ProductKey]
,[OrderQuantity]
,[UnitPrice]
,[ExtendedAmount]
,[DiscountAmount]
,[ProductStandardCost]
,[TotalProductCost]
,[SalesAmount]
,[TaxAmt]
FROM [FactInternetSales]
ORDER BY [ProductKey]
为了尽可能使这个例子简单,我们创建了一个新表,然后将上述数据插入到新表中。
CREATE TABLE [dbo].[DupFactInternetSales]( [FactID] [int] IDENTITY(1,1) NOT NULL, [ProductKey] [int] NOT NULL, [OrderQuantity] [smallint] NOT NULL, [UnitPrice] [money] NOT NULL, [ExtendedAmount] [money] NOT NULL, [DiscountAmount] [float] NOT NULL, [ProductStandardCost] [money] NOT NULL, [TotalProductCost] [money] NOT NULL, [SalesAmount] [money] NOT NULL, [TaxAmt] [money] NOT NULL ) ON [PRIMARY] GO
下面的屏幕截图将向你展示我们插入到数据库的 DupFactInternetSales 表中的数据。
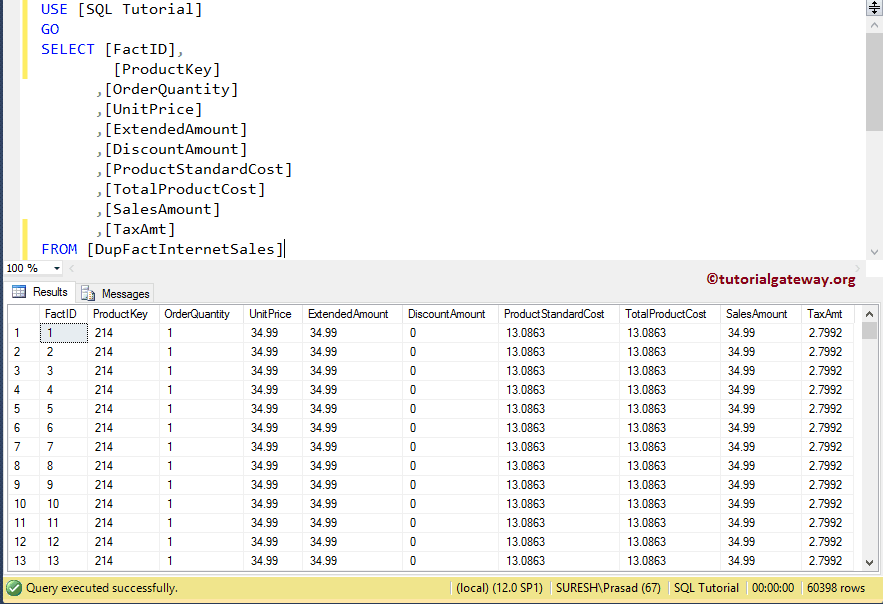
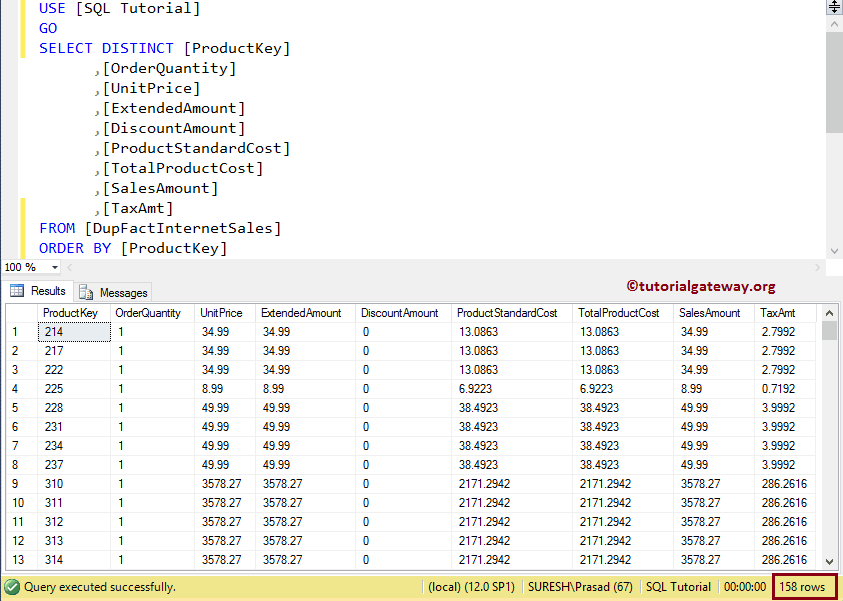
让我向你展示 SQL Server 表中存在的唯一记录。正如你所见,我们使用了 SELECT DISTINCT 关键字。
使用 ROW_NUMER 和 CTE 删除 SQL Server 中的重复行
在本例中,我们将向你展示如何使用 ROW_NUMBER 函数和公共表表达式(CTE)来删除重复行。
WITH RemoveDuplicate
AS (
SELECT ROW_NUMBER()
OVER (
PARTITION BY [ProductKey]
,[OrderQuantity]
,[UnitPrice]
,[ExtendedAmount]
,[DiscountAmount]
,[ProductStandardCost]
,[TotalProductCost]
,[SalesAmount]
,[TaxAmt]
ORDER BY [ProductKey]
) UniqueRowNumber
FROM [DupFactInternetSales])
DELETE FROM RemoveDuplicate
WHERE UniqueRowNumber > 1;
在 CTE 中,我们使用了名为 ROW_NUMBER 的排序函数。它将分配一个从 1 到 n 的唯一排序编号。接下来,我们删除所有排序编号大于 1 的记录。
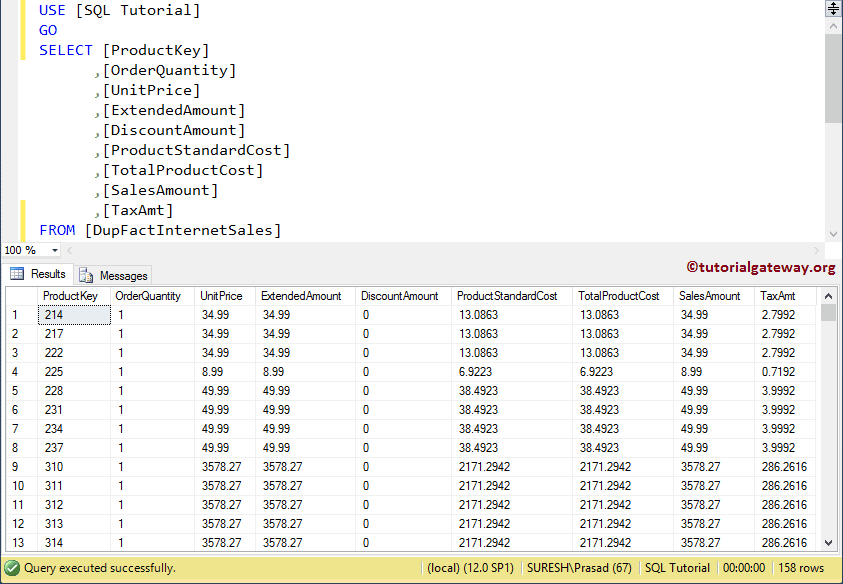
输出:让我向你展示该语句的输出。
Messages
--------
(60240 row(s) affected)让我们看看在删除操作后,DupFactInternetsales 中存在的数据。
使用自连接删除 SQL Server 中的重复行
在这个常见问题解答中,我们将展示如何使用 SELF JOIN 来移除重复行。
DELETE InternetSales
FROM [DupFactInternetSales] InternetSales,
[DupFactInternetSales] FactInternetSales
WHERE InternetSales.[ProductKey] = FactInternetSales.[ProductKey] AND
InternetSales.[OrderQuantity] = FactInternetSales.[OrderQuantity] AND
InternetSales.[UnitPrice] = FactInternetSales.[UnitPrice] AND
InternetSales.[ExtendedAmount] = FactInternetSales.[ExtendedAmount] AND
InternetSales.[DiscountAmount] = FactInternetSales.[DiscountAmount] AND
InternetSales.[ProductStandardCost]= FactInternetSales.[ProductStandardCost] AND
InternetSales.[SalesAmount] = FactInternetSales.[SalesAmount] AND
InternetSales.[TaxAmt] = FactInternetSales.[TaxAmt] AND
InternetSales.FactID > FactInternetSales.FactID
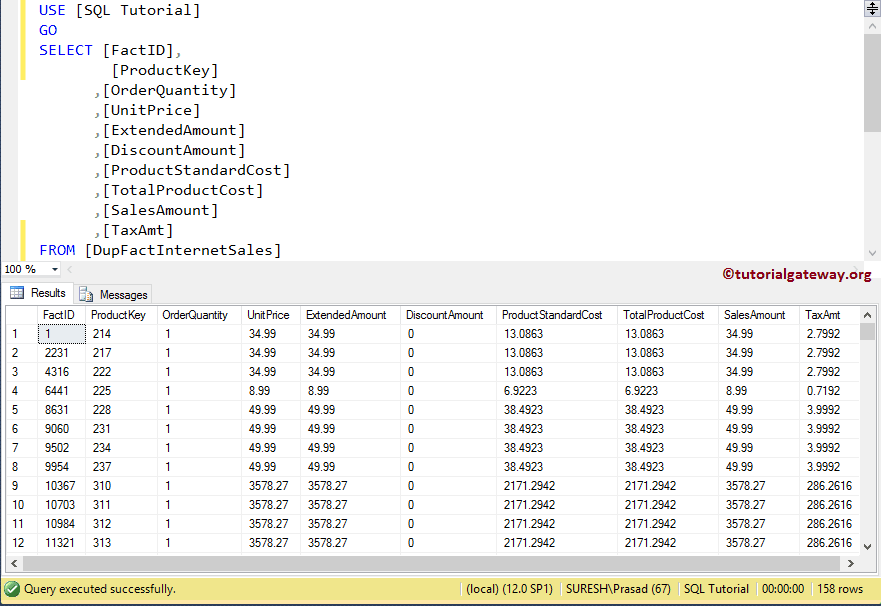
让我向你展示该语句的输出。
Messages
--------
(60240 row(s) affected)输出
使用 Group By Having 子句删除重复行
此示例展示了如何使用 LEFT JOIN、MIN 函数、GROUP BY 和 HAVING 来删除重复行。
DELETE DupFactInternetSales
FROM DupFactInternetSales
LEFT JOIN (
SELECT MIN([FactID]) AS [FactID]
,[ProductKey]
,[OrderQuantity]
,[UnitPrice]
,[ExtendedAmount]
,[DiscountAmount]
,[ProductStandardCost]
,[TotalProductCost]
,[SalesAmount]
,[TaxAmt]
FROM [DupFactInternetSales]
GROUP BY [ProductKey],
[OrderQuantity]
,[UnitPrice]
,[ExtendedAmount]
,[DiscountAmount]
,[ProductStandardCost]
,[TotalProductCost]
,[SalesAmount]
,[TaxAmt]
) AS InternetSales ON
[DupFactInternetSales].[FactID] = InternetSales.[FactID]
WHERE InternetSales.[FactID] IS NULL
让我向你展示该语句的输出。
Messages
--------
(60240 row(s) affected)