R 中的数据框(Data Frame)是一个表格或二维数据结构。在数据框中,记录存储在行和列中,我们可以使用行索引和列索引来访问元素。以下是它的一些特性:
- 数据框是变量的列表,并且必须包含相同数量的具有唯一行名的行。
- 列名不应为空。
- 虽然数据框通过使用 `check.names = FALSE` 支持重复的列名。但始终建议使用唯一的列名。
- 其中存储的数据可以是字符型(Character)、数值型(Numerical)或因子型(Factors)。
在本文中,我们将向您展示如何在 R 编程中创建数据框以及如何访问列和行。我们还将介绍如何操作单个元素、行级或列级元素,以及创建命名数据框。此外,文章还将解释数据框支持的一些重要函数。
如何在 R 中创建数据框
此示例创建了一个包含不同元素的数据框,最常见的方法是:
Id <- c(1:10)
Name <- c("John", "Rob", "Ruben", "Christy","Johnson", "Miller", "Carlson", "Ruiz", "Yang","Zhu")
Occupation <- c("Professional", "Programmer","Management", "Clerical",
"Developer", "Programmer", "Management", "Clerical", "Developer","Programmer")
Salary <- c(80000, 70000, 90000, 50000, 60000, 75000, 92000, 68000, 55000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
首先,我们创建了四个不同类型向量,然后使用这四个向量创建了数据框。
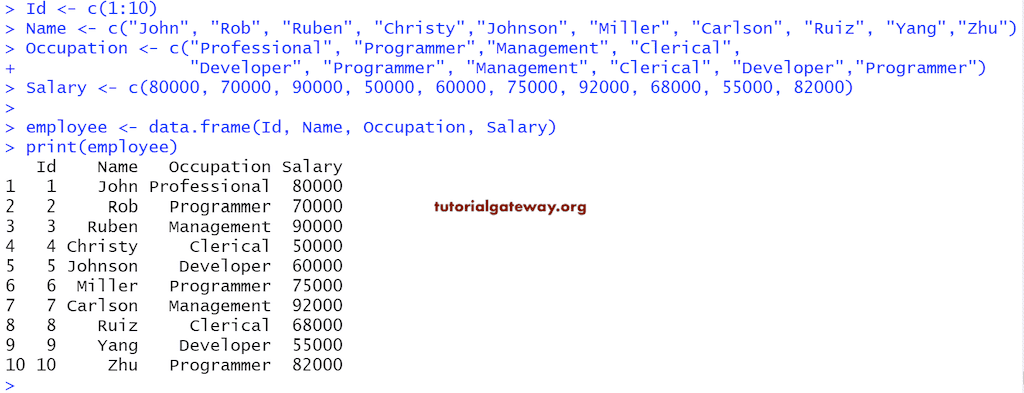
在 R 中创建命名数据框
这展示了在此编程中创建命名数据框的步骤,其语法为:
DataFrame_Name <- data.frame(“index_Name1” = Item1, “index_Name2″ = Item2,… ,”index_NameN” = ItemN )
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer", "Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
# We are assigning new names to the Columns
employee <- data.frame("Empid" = Id, "Full_Name" = Name, "Profession" = Occupation, "income" = Salary)
print(employee)
# Names function will display the Index Names of each Item
print(names(employee))

访问 R 数据框元素
我们可以通过多种方式访问数据框元素。这里,我们将向您展示如何使用索引位置访问元素。索引值从 1 开始,到 n 结束,其中 n 是元素的数量。
例如,如果我们声明一个存储十个元素(10 列)的数据框,索引从 1 开始,到 10 结束。要访问第一个值,请使用 `DataFrame_Name[1]`;要访问第十个值,请使用 `DataFrame_Name[10]`。
我们还可以使用双括号 `[[` 来访问数据框元素。此示例向您展示如何使用 `[[` 访问元素。它将以 R 编程向量(带有级别信息)的形式返回结果。
# Accessing Elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer", "Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
# Accessing all the Elements (Rows) Present in the Name Items (Column)
employee["Name"]
# Accessing all the Elements (Rows) Present in the 3rd Column (i.e., Occupation)
employee[3] # Index Values: 1 = Id, 2 = Name, 3 = Occupation, 4 = Salary

使用 `[[` 访问元素
我们还可以使用双括号 `[[` 来访问数据框元素。此示例展示了如何使用 `[[` 访问数据框项。它将以带有级别信息的向量形式返回结果。
# Accessing Elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer", "Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
employee[["Name"]]
employee[[3]]
它返回与上述示例相同的结果。但是,它返回的是一个向量而不是一个数据框。

使用 `$` 访问 R 数据框项
我们还可以使用 `$` 符号来访问元素。在此示例中,我们将展示如何使用 `$` 访问数据框的元素。它将以带有级别信息的向量形式返回结果。其语法是:`
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer", "Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
# Get all the Elements (Rows) Present in the Name Item (Column)
employee$Name
# Get all the Elements (Rows) Present in the Salary Item (Column)
employee$Salary

访问低级别元素
在 R 编程中,我们可以使用索引位置来访问数据框项的低级别元素(或单个单元格)。使用此索引值,我们可以访问每个单独的项。索引值从 1 开始,到 n 结束,其中 n 是行或列中的元素数量。其语法是 `[Row_Number, Column_Number]`。
例如,如果我们声明一个包含六行元素和四列元素的数据框。要访问或修改第一个值,请使用 `DataFrame_Name[1, 1]`;要访问第二行第三列的值,请使用 `DataFrame_Name[2, 3]`;要访问第六行第四列,请使用 `DataFrame_Name[6, 4]`。
# Accessing Low level elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer", "Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
# Accessing Element at 1st Row and 2nd Column
employee[1, 2]
# Get Element at 4th Row and 3rd Column
employee[4, 3]
# Get All Elements at 5th Row
employee[5, ]
# Get All Item of the 4th Column
employee[, 4]

访问多个值
这展示了如何访问数据框的多个项。要实现这一点,我们使用 R 向量。
# Accessing Subset of elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer", "Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
# Accessing Item at 1st, 2nd Rows and 3rd, 4th Columns
employee[c(1, 2), c(3, 4)]
# Accessing Item at 2nd, 3rd, 4th Rows and 2nd, 4th Columns
employee[2:4, c(2, 4)]
# getting All Item at 2nd, 3rd, 4th, 5th Rows
employee[2:5, ]
# Printing All Item of 2nd and 4th Column
employee[c(2, 4)]

使用 `$` 访问低级别元素
使用 `$` 符号,我们还可以使用 `$` 符号以低级别(单个单元格)访问数据框的元素。让我们看看如何使用 `$` 访问单个单元格。它将以带有级别信息的向量形式返回结果。
# Accessing elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Occupation <- c("Professional", "Management", "Developer",
"Programmer", "Clerical", "Admin")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
# Accessing Item at 2nd, 4th Rows of Name Columns
employee$Name[c(2, 4)]
# getting Item at 2nd, 3rd, 4th, 5th Rows of Occupation Column
employee$Occupation[2:5]

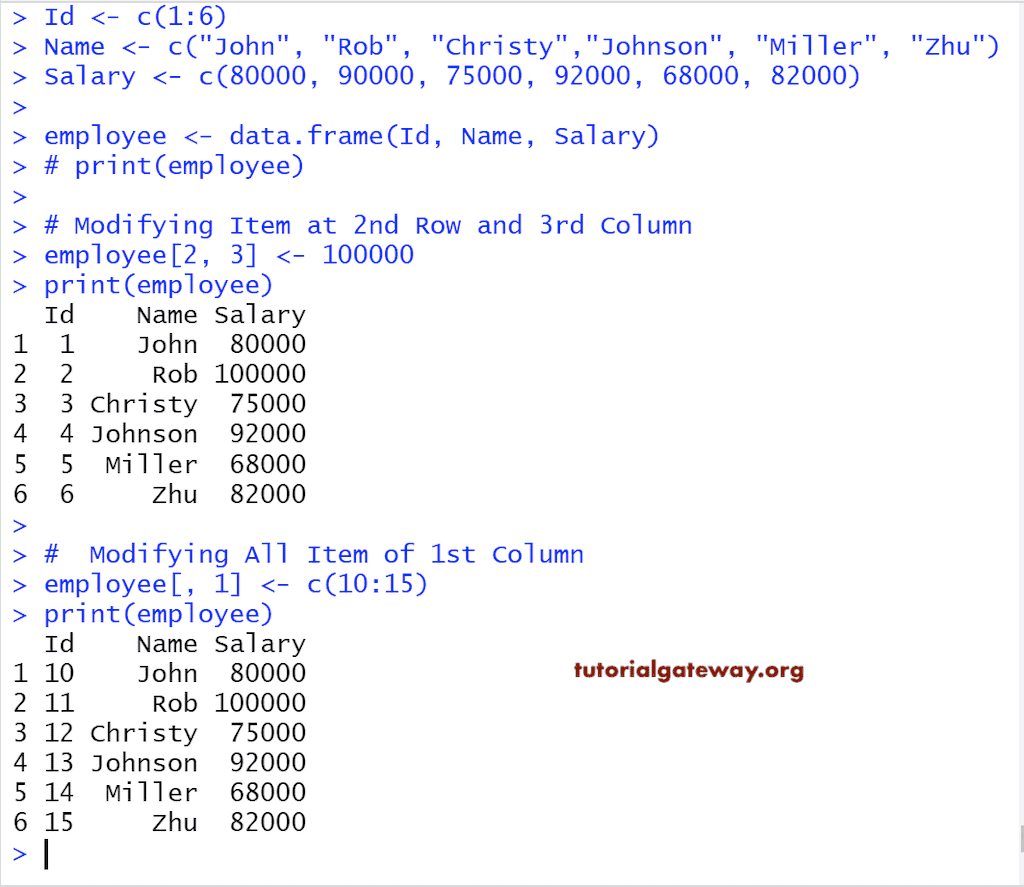
修改 R 数据框元素
我们可以使用索引位置来访问元素和提取数据。使用此索引值,我们可以修改或更改每个单独的元素。在此,我们将修改特定单元格的值和整个列项。
# Modifying elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Salary)
print(employee)
# Modifying Item at 2nd Row and 3rd Column
employee[2, 3] <- 100000
print(employee)
# Modifying All Item of 1st Column
employee[, 1] <- c(10:15)
print(employee)
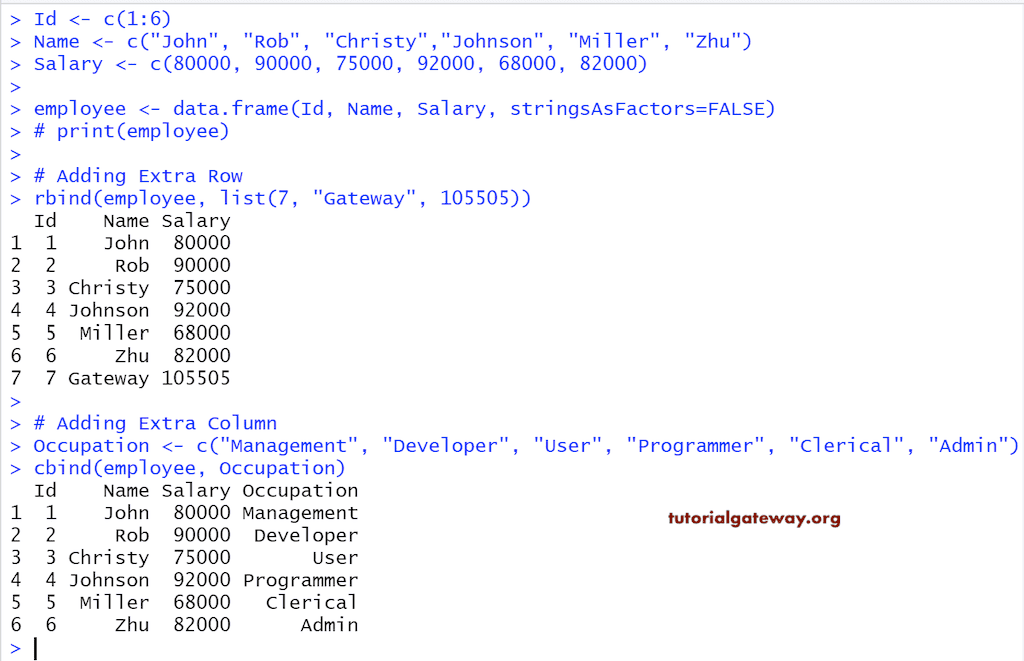
添加元素
此示例向现有数据框添加新元素。
- `cbind(DataFrame, Values)`:`cbind` 函数会添加具有值的额外列。我们通常偏好使用向量作为 `values` 参数。
- `rbind(DataFrame, Values)`:`rbind` 函数会添加具有值的额外行。
# Adding elements
Id <- c(1:6)
Name <- c("John", "Rob", "Christy","Johnson", "Miller", "Zhu")
Salary <- c(80000, 90000, 75000, 92000, 68000, 82000)
employee <- data.frame(Id, Name, Salary, stringsAsFactors=FALSE)
print(employee)
# Adding Extra Row
rbind(employee, list(7, "Gateway", 105505))
# Adding Extra Column
Occupation <- c("Management", "Developer", "User", "Programmer", "Clerical", "Admin")
cbind(employee, Occupation)
R 数据框的重要函数
以下数据框函数是最有用的函数。
- `typeof(DataFrame)`:返回数据类型。由于它是一种列表(list),因此返回 `list`。
- `class(DataFrame)`:返回其类。
- `length(DataFrame)`:计算其中项目的数量(列数)。
- `nrow(DataFrame)`:返回存在的总行数。
- `ncol(DataFrame)`:返回总列数。
- `dim(DataFrame)`:返回存在的总行数和列数。
# Important Functions
Id <- c(1:10)
Name <- c("John", "Rob", "Ruben", "Christy","Johnson", "Miller", "Carlson", "Ruiz", "Yang","Zhu")
Occupation <- c("Professional", "Programmer","Management", "Clerical",
"Developer", "Programmer", "Management", "Clerical", "Developer","Programmer")
Salary <- c(80000, 70000, 90000, 50000, 60000, 75000, 92000, 68000, 55000, 82000)
#employee <- data.frame("empid" = Id, "name" = Name, "Profession" = Occupation, "income" = Salary)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
typeof(employee)
class(employee)
names(employee)
# Number of Rows and Columns
length(employee)
ncol(employee)
nrow(employee)
dim(employee)

R 数据框的 Head 和 Tail 函数
如果您的记录太多,并且您想提取表现最佳的记录,那么您可以使用这些数据框函数。
- `head(DataFrame, limit)`:返回前六个元素(如果您省略 `limit`)。例如,如果您将 `limit` 指定为 2,它将返回前两条记录。这有点像选择前 10 条记录。
- `tail(DataFrame, limit)`:返回最后六个元素(如果您省略 `limit`)。例如,如果您将 `limit` 指定为 4,它将返回最后四条记录。
# Head and Tail Function
Id <- c(1:10)
Name <- c("John", "Rob", "Ruben", "Christy", "Johnson", "Miller", "Carlson", "Ruiz", "Yang","Zhu")
Occupation <- c("Professional", "Programmer","Management", "Clerical", "Developer", "Programmer",
"Management", "Clerical", "Developer","Programmer")
Salary <- c(80000, 70000, 90000, 50000, 60000, 75000, 92000, 68000, 55000, 82000)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
# No limit - It means Displaying First Six Records
head(employee)
# Limit is 4 - It means Displaying First Four Records
head(employee, 4)
# No limit - It means Displaying Last Six Records
tail(employee)
# Limit is 4 - It means Displaying Last Six Records
tail(employee, 4)

R 数据框特殊函数
以下两个是非常有用的函数。在开始操作或插入新记录之前,最好检查结构。
- `str(DataFrame)`:返回其结构。
- `summary(DataFrame)`:它返回数据的性质以及最小值、中位数、平均值、中位数等统计摘要。
# Important Functions
Id <- c(1:10)
Name <- c("John", "Rob", "Ruben", "Christy","Johnson", "Miller", "Carlson", "Ruiz", "Yang","Zhu")
Occupation <- c("Professional", "Programmer","Management", "Clerical",
"Developer", "Programmer", "Management", "Clerical", "Developer","Programmer")
Salary <- c(80000, 70000, 90000, 50000, 60000, 75000, 92000, 68000, 55000, 82000)
#employee <- data.frame("empid" = Id, "name" = Name, "Profession" = Occupation, "income" = Salary)
employee <- data.frame(Id, Name, Occupation, Salary)
print(employee)
print(str(employee))
print(summary(employee))
